

Choisir le bon accélérateur d'Ascend AI pour l'inférence Edge
Vous êtes confronté à de nombreux choix lorsque vous sélectionnez les accélérateurs Ascend AI pour l'inférence de bord. Vous devez correspondre aux besoins de votre application pour

Vous êtes confronté à de nombreux choix lorsque vous sélectionnez les accélérateurs Ascend AI pour l'inférence de bord. Vous devez faire correspondre les besoins de votre application en matière de performances, de puissance et de coût avec les bonnes fonctionnalités matérielles. L'Edge AI se développe rapidement. Le marché mondial atteint20,78 milliards de dollarsEn 2024 avec un TCAC de 21,7%. De nombreuses applications nécessitent désormais des temps de réponse de moins de 50 millisecondes. L'inférence AI en temps réel est importante pour les caméras, les véhicules et les robots intelligents. Les accélérateurs d'Ascend AI fonctionnent avec les systèmes Edge et Cloud, ce qui vous donne de la flexibilité. Vous trouverez de nombreux modèles. Chacune s'adapte à différentes tâches telles que l'analyse d'image, les grands modèles de langage ou les environnements difficiles.
| Métrique | Valeur |
|---|---|
| Évaluation 2024 | 20,78 milliards de dollars |
| Taux de croissance | 21,7% TCAC |
| Exigence de performance | Temps de réponse Sub-50ms |
Conseil: concentrez-vous sur votre cas d'utilisation et votre environnement pour trouver le meilleur ajustement.
Les clés à emporter
- Identifiez d'abord les besoins de votre application. Concentrez-vous sur les performances, la puissance et le coût pour choisir le bon accélérateur d'Ascend AI.
- Considérez le facteur de forme de l'accélérateur. Sélectionnez une taille adaptée à votre environnement de déploiement, qu'il soit compact pour les drones ou plus grand pour les centres de données.
- Évaluer l'efficacité de la puissance. Choisissez des accélérateurs qui minimisent la consommation d'énergie pour réduire les coûts et prolonger la durée de vie de l'appareil, en particulier pour les applications edge.
- VérifierCompatibilité avec les frameworks logiciels. Assurez-vous que vos modèles d'IA fonctionnent de manière transparente avec des outils populaires tels que TensorFlow et PyTorch pour éviter les problèmes d'intégration.
- Testez vos modèles d'IA sur le matériel sélectionné. Cette étape garantit que les performances répondent à vos exigences de vitesse et de précision avant le déploiement complet.
Aperçu des accélérateurs d'Ascend AI

Famille de produits
Vous pouvez trouver de nombreuses options dans leLigne d'accélérateur d'Ascend AI. Ces plates-formes vous aident à exécuter des tâches AI à la périphérie et dans le cloud. ChaqueFamille de produitsA un rôle spécial. Certaines plateformes se concentrent sur l'inférence de bord, tandis que d'autres prennent en charge les charges de travail AI basées sur le cloud.
| Famille de produits | Rôle principal dans l'inférence Edge et Cloud |
|---|---|
| Processeurs Ascend AI | Couche de la puce de base dans la pile complète, architecture évolutive |
| Atlas AI informatique | Fournit divers facteurs de forme de produit pour les infrastructures d'IA |
| Module AI Atlas 200 | Conçu pour les applications de bord |
| Carte d'AI de l'atlas 300 | Utilisé dans les environnements cloud |
| Station AI Atlas 500 | Cible les solutions informatiques de périphérie |
| Serveurs Atlas 800 AI | Prend en charge les applications d'IA basées sur le cloud |
Vous pouvez utiliser ces plateformes pourConstruire des solutions flexibles ai. Les accélérateurs Ascend ai vous donnent le pouvoir de traiter rapidement les données. Vous pouvez choisir les bonnes plates-formes pour vos besoins, que vous souhaitiez exécuter l'IA à la périphérie ou dans le cloud.
Intégration Edge et Cloud
Les accélérateurs Ascend ai fonctionnent bien avec les plates-formes Edge et Cloud. Vous pouvez déployer des modèles AI sur différents appareils et obtenir des résultats rapides. Certains accélérateurs sont petits et s'adaptent à des systèmes compacts. D'autres travaillent dans de grands serveurs pour de lourdes charges de travail AI.
Voici quelques modèles et périphériques clés que vous pourriez utiliser pour l'inférence de bord:
- Ascend 310: Cette puce fait partie de la gamme Atlas. Vous pouvez l'utiliser pour de nombreuses applications ai.
- Atlas 200: Ce module d'accélérateur AI compact offre jusqu'à16 téraflops de puissance de calcul. Il utilise seulement 8 à 13,8 watts.
- Atlas 500: Cette solution de bord fournit 16 téraflops (INT8) ou 8 téraflops (FP16). Il prend en charge le traitement en temps réel et utilise 25 à 40 watts.
Vous pouvez mélanger et assortir ces plates-formes pour adapter votre projet. Les accélérateurs Ascend ai vous aident à construire des systèmes intelligents qui répondent rapidement. Vous pouvez exécuter des tâches AI sur le bord pour des résultats rapides ou envoyer des données vers le cloud pour une analyse plus approfondie.
Remarque: Vous devez toujours vérifier la puissance et les performances de chaque accélérateur avant de choisir une plate-forme. Cela vous aide à obtenir les meilleurs résultats pour votre application ai.
Inférence AI au bord

Inférence en temps réel
Vous avez besoin de réponses rapides et fiables pour de nombreuses applications modernes. L'inférence AI à la périphérie vous permet de traiter les données à proximité de leur lieu de création. Cette approche apporte plusieurs avantages importants:
- Traitement en temps réelVous obtenez des résultats immédiats car l'appareil gère les données localement. Cela est essentiel pour l'inférence AI en temps réel dans les caméras intelligentes, les véhicules autonomes et la surveillance des soins de santé.
- Confidentialité et sécurité: vous conservez des informations sensibles sur l'appareil, ce qui réduit le risque de fuites de données pendant la transmission.
- Efficacité de la bande passante: vous envoyez moins de données vers le cloud, ce qui économise les ressources réseau et réduit les coûts. Cela aide dans les régions éloignées avec une connectivité limitée.
- Évolutivité: Vous pouvez ajouter plus d'appareils de périphérie à mesure que vos besoins augmentent. Cela ne surcharge pas vos systèmes centraux.
- Efficacité énergétique: les appareils Edge utilisent moins d'énergie car ils évitent la transmission constante de données.
- Opération hors ligne: Votre inférence AI peut continuer à fonctionner même si la connexion Internet tombe.
Astuce: L'inférence ai en temps réel à la périphérie réduit la latence. Vous obtenez des décisions plus rapides et de meilleures expériences utilisateur.
Accélération matérielle
Vous pouvez améliorer les performances d'inférence ai avecAccélération matérielle. Des puces spéciales comme les GPU gèrent de nombreuses tâches à la fois. Ceci faitTraitement en temps réelPossible pour les charges de travail exigeantes d'ai. Vous voyez cela en action avec l'analyse vidéo en temps réel pour la sécurité, la maintenance prédictive dans les usines et les contrôles qualité automatisés dans la fabrication.
L'accélération matérielle vous permet d'analyser les données rapidement et de prendre des décisions sans attendre les serveurs cloud. Cela réduit la latence et garde vos informations privées. Vous améliorez également la consommation d'énergie et prenez en charge plus de charges de travail AI sur chaque appareil. Avec la bonne optimisation, vous pouvez exécuter des tâches d'inférence complexes de manière fluide et fiable.
Remarque: L'accélération matérielle est essentielle pour l'inférence ai en temps réel. Il vous aide à répondre à des exigences de latence strictes et à gérer de lourdes charges de travail AI à la périphérie.
Critères de sélection
Choisir le bon accélérateur Ascend AI pour l'inférence de bord signifie que vous devez examiner plusieurs facteurs importants. Vous voulez vous assurer que vos applications d'IA fonctionnent bien et atteignent vos objectifs en matière de coût, d'efficacité énergétique et de performance. Voici les principaux critères que vous devriez considérer:
Performance
Vous devez faire correspondre les performances de l'accélérateur à vos applications ai. Certaines tâches, comme l'analyse d'image ou l'inférence vidéo, nécessitent une puissance de calcul élevée. D'autres, comme les simplesCapteurTraitement des données, besoin de moins. Vous devriez vérifier le nombre de téraflops,MémoireBande passante et types de données pris en charge. L'inférence rapide aide vos applications à répondre en temps réel. Si vous travaillez avec de grands modèles de langage ou des charges de travail complexes, vous avez besoin d'un accélérateur avec de fortes performances. Vous devriez également regarder comment l'accélérateur gère plusieurs tâches à la fois.
Conseil: testez toujours vos modèles AI sur le matériel cible pour voir si la vitesse d'inférence répond à vos exigences.
Efficacité de puissance
L'efficacité énergétique est essentielle pour les déploiements en périphérie. Vous voulez que vos applications ai fonctionnent pendant de longues périodes sans surchauffer ou vider les batteries. L'Ascend 910C se distingue par son efficacité énergétique. Il utilise environ310WCe qui contribue à réduire le coût total de possession. D'autres accélérateurs, comme le NVIDIA H100, offrent des performances plus brutes mais consomment beaucoup plus d'énergie. Vous devez comparer la consommation d'énergie de chaque accélérateur et choisir celui qui correspond à vos besoins de déploiement. Consommation d'énergie plus faible signifie moins de chaleur et une plus longue durée de vie de l'appareil.
- Ascend 910C offre une forte efficacité énergétique pour l'inférence de bord.
- L'utilisation moins d'énergie aide à réduire les coûts et prend en charge les applications AI durables.
- Une efficacité énergétique élevée signifie que vous pouvez déployer plus d'appareils sans augmenter votre budget énergétique.
Facteur de forme
Le facteur de forme de l'accélérateur affecte l'endroit où vous pouvez déployer vos applications ai. Vous devez choisir une taille et une forme qui correspondent à votre environnement. Certains accélérateurs sont petits et légers, parfaits pour les drones ou les caméras. D'autres sont plus grands et fonctionnent mieux dans les serveurs de périphérie ou les centres de données. Le tableau ci-dessous présente différents facteurs de forme et leur impact sur le déploiement:
| Facteur de forme | Description | Impact du déploiement |
|---|---|---|
| Accélérateur d'AI de l'atlas 200 | Module compact, moitié de la taille d'une carte de crédit,10 watts consommation d'énergie | Idéal pour les appareils tels que les caméras et les drones, permettant l'analyse vidéo HD en temps réel. |
| Accélérateur Atlas 300 AI | Carte standard HHHL PCIe pour les centres de données et les serveurs de périphérie | Prend en charge plusieurs précisions de données, offrant des performances élevées pour les tâches de deep learning et d'inférence. |
| Station de périphérie Atlas 500 AI | Intègre le traitement AI dans une taille de boîtier décodeur | Convient pour diverses applications, y compris le transport et les soins de santé, avec des améliorations significatives des performances. |
| Appareil Atlas 800 AI | Environnement IA optimisé avec logiciel préinstallé | Prêt à l'emploi rapidement, intègre un logiciel de gestion pour les applications d'IA d'entreprise, réduisant ainsi les barrières à l'entrée. |
Vous devez choisir un facteur de forme qui correspond à votre espace de déploiement et aux besoins de vos applications AI.
Coût
Le coût est un facteur important lorsque vous sélectionnez un accélérateur pour l'inférence de bord. Vous devez regarder le prix du matériel, le coût de l'énergie et le coût de la maintenance. Certains accélérateurs coûtent plus cher au départ, mais économisent de l'argent au fil du temps en raison d'une meilleure efficacité énergétique. L'Ascend 910C, par exemple, offre une bonne efficacité énergétique, ce qui réduit le coût total de possession. Vous devriez également tenir compte du coût des licences logicielles et du support. Si vous envisagez de faire évoluer vos applications d'IA, vous devez penser au coût de l'ajout d'accélérateurs.
- Le coût du matériel affecte votre budget pour les applications AI.
- Les coûts énergétiques ont une incidence sur les économies à long terme.
- Le coût de maintenance comprend les mises à jour et les réparations.
- Le coût total de possession combine tous ces facteurs.
Remarque: Calculez toujours le coût total avant de choisir un accélérateur. Cela vous aide à éviter les surprises et assure le bon fonctionnement de vos applications AI.
Compatibilité
La compatibilité avec votre matériel et logiciel existant est essentielle. Vous souhaitez que vos applications AI fonctionnent avec des frameworks populaires tels que TensorFlow et PyTorch. Les plates-formes Ascend prennent en charge ces frameworks, ce qui facilite l'intégration. Huawei aOpen source CANNPour aider les développeurs à s'éloigner des fabricants de puces occidentaux. L'écosystème est encore en croissance, vous pouvez donc faire face à certains défis. Huawei fournit également des adaptateurs pour les modèles PyTorch sur les NPU Ascend. Cet accent mis sur l'interopérabilité vous aide à basculer sans perdre la prise en charge de vos applications AI. MindSpore offre une autre option pour la construction et la gestion des charges de travail AI.
- Ascend prend en charge TensorFlow, PyTorch et MindSpore pour les applications AI.
- Les outils open source vous aident à migrer vos charges de travail d'inférence.
- La compatibilité réduit les coûts d'intégration et accélère le déploiement.
Astuce: Vérifiez la compatibilité de vos modèles et logiciels d'IA avant de choisir un accélérateur. Vous économisez ainsi du temps et des coûts lors du déploiement.
Correspondant aux exigences des applications
Vous devez toujours faire correspondre les critères de sélection à vos applications spécifiques. Si vous travaillez avec une analyse d'image ou de vidéo, vous avez besoin de haute performance et d'efficacité énergétique. Pour les grands modèles de langage, vous avez besoin de plus de mémoire et de puissance de calcul. Les conditions environnementales comptent également. Certains accélérateurs fonctionnent mieux dans des endroits difficiles ou éloignés. Vous devez lister vos besoins et les comparer aux caractéristiques de chaque accélérateur.
- L'inférence en temps réel pour les caméras et les drones nécessite des accélérateurs compacts et économes en énergie.
- Les applications de soins de santé et de transport peuvent nécessiter des facteurs de forme plus importants et des performances plus élevées.
- Le coût et la compatibilité affectent la rapidité avec laquelle vous pouvez déployer et mettre à l'échelle vos applications AI.
N'oubliez pas: le meilleur accélérateur pour votre inférence de bord dépend des besoins de votre application, des limites de coûts, des objectifs d'efficacité énergétique et de la compatibilité avec vos systèmes existants.
Comparaison de modèle
Choisir le bon accélérateur Ascend AI pour l'inférence de bord signifie comprendre ce que chaque modèle offre. Vous voulez faire correspondre votre application avec le meilleur matériel. Examinons quatre options populaires: Ascend 310, Ascend 910C, Atlas 200 et Atlas 500 Pro.
Ascend 310
L'Ascend 310 vous offre un équilibre entre performance et efficacité. Vous pouvez l'utiliser dans de nombreux scénarios Edge AI. Cette puce fonctionne bien dans les petits appareils et prend en charge le traitement en temps réel. Il gère jusqu'à200 visages ou objetsÀ la fois, ce qui le rend idéal pour la sécurité et la surveillance.
| Cas d'utilisation | Description |
|---|---|
| Caméras de sécurité | Traite 200 faces ou objets en même temps. Parfait pour la surveillance en temps réel. |
| Drones | Stimule les fonctionnalités autonomes et prend en charge diverses tâches AI. |
| Commerce de détail autonome intelligent | Pouvant solutions ai-driven dans la vente au détail, l'amélioration de l'expérience client et de l'efficacité. |
| Surveillance des chantiers de construction | Aide les entreprises de construction à suivre les activités sur place. |
| Surveillance de ligne électrique | Permet aux fournisseurs de services publics de surveiller efficacement les lignes électriques. |
Vous pouvez déployer Ascend 310 dans des endroits où vous avez besoin d'une inférence rapide, mais où l'espace ou la puissance sont limités. Il s'intègre bien dans les caméras intelligentes, les drones et les systèmes de vente au détail.
Ascend 910C
Ascend 910C se distingue par sa puissance de calcul élevée et son efficacité énergétique. Vous obtenez jusqu'à320 TFLOPS de performance FP16. Cette puce utilise environ 310 watts, ce qui est inférieur à de nombreux GPU concurrents. Cela fonctionne bien pour le deep learning et les grands modèles AI.
| Métrique | Ascend 910C | NVIDIA NVL72 B200 |
|---|---|---|
| Consommation électrique (par GPU) | 70 à 80% du NVIDIA NVL72 | 100% |
| Performance globale du supernœud (FLOPS) | 70% plus élevé que NVL72 | 100% |
| Consommation d'énergie par FLOP | 2,3 fois plus élevé | 1.0 |
| Consommation électrique par bande passante de la mémoire TB/s | 1,8 fois plus élevé | 1.0 |
| Consommation par TB de capacité de mémoire HBM | 1,1 fois plus élevé | 1.0 |
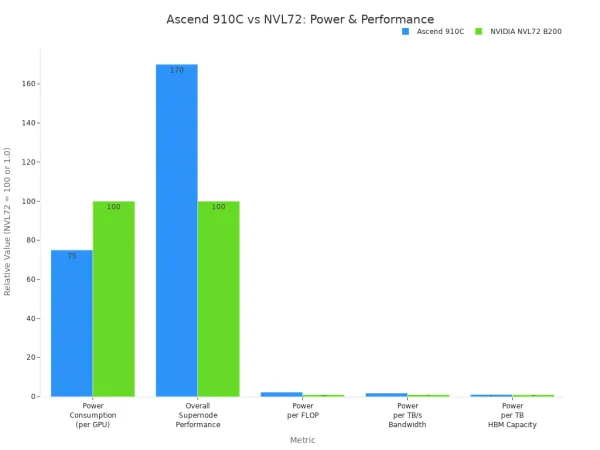
Vous pouvez utiliser Ascend 910C pour les charges de travail AI exigeantes. Il convient le mieux aux serveurs de périphérie ou aux centres de données où vous avez besoin de performances élevées et de coûts énergétiques réduits. Ce modèle est idéal pour la formation et la gestion de grands modèles AI en temps réel.
Note: Ascend 910C est en concurrence avec les meilleurs GPU comme NVIDIA A100 et H100. Vous obtenez des performances élevées et économisez de l'énergie.
Atlas 200
Atlas 200 est un module accélérateur compact AI. Il est à propos deMoitié de la taille d'une carte de crédit. Vous pouvez l'utiliser dans des appareils terminaux tels que des caméras, des robots et des drones. Ce module prend en charge l'analyse vidéo HD en temps réel 16 canaux. Vous obtenez un traitement ai fort dans un petit paquet.
- Vous pouvez déployer Atlas 200 dans des caméras pour une surveillance intelligente.
- Cela fonctionne bien dans les robots pour la prise de décision en temps réel.
- Les drones utilisent Atlas 200 pour la navigation et la surveillance alimentées par l'IA.
L'Atlas 200 gère les environnements difficiles. Il fonctionne à des températures de-20 °C à 55 °C et peut supporter les chocs et les vibrations. Cela en fait un bon choix pour les applications AI extérieures ou mobiles.
| Facteur environnemental | Spécification |
|---|---|
| Température de stockage | -30 à 60 °C |
| Température de fonctionnement | -20 à 55 °C ambiant |
| Humidité | Fonctionnement: 20% ~ 80%, relatif, sans condensation |
| Test | Norme | Paramètres |
|---|---|---|
| Choc | DIN EN 60068-2-27 | Chaque axe (x/y/z), 20g, 11ms, /- 10 chocs |
| Bosse | DIN EN 60068-2-27 | Chaque axe (x/y/z), 20g, 11ms, /- 100 bosses |
| Vibration (aléatoire) | DIN EN 60068-2-64 | Chaque axe (x/y/z), 4,9g RMS, 15-500Hz, accélération 0,05g 2/Hz, 30min par axe |
| Vibration (sinusoïdale) | DIN EN 60068-2-6 | Chaque axe (x/y/z), 10-58Hz: 1,5mm, 58-500Hz: 10g, 1 oct/min, 1 heure 52 min par axe |
Astuce: Atlas 200 est un choix fort pour l'IA à la périphérie, en particulier dans les environnements difficiles ou mobiles.
Pro Atlas 500
Atlas 500 Pro vous offre une solution d'ai de bord puissante dans une taille de boîtier décodeur. Vous pouvez l'utiliser pour l'analyse vidéo en temps réel, le transport intelligent et les soins de santé. Ce dispositif soutient jusqu'à 16 teraflops (INT8) ou 8 teraflops (FP16) de puissance de calcul. Il utilise entre 25 et 40 watts, ce qui le rend économe en énergie.
Vous pouvez déployer Atlas 500 Pro dans des endroits où vous avez besoin de fortes performances AI, mais où vous n'avez pas de place pour les grands serveurs. Il s'intègre bien dans les projets de ville intelligente, les hôpitaux et les centres de transport. Vous obtenez une inférence AI fiable et une intégration facile avec les systèmes existants.
Points forts de l'Atlas 500 Pro:
- Offre des performances AI élevées pour les applications de bord.
- Prend en charge l'analyse en temps réel des données vidéo et des capteurs.
- Fonctionne dans des environnements où l'espace et la puissance sont limités.
Callout: Atlas 500 Pro vous aide à apporter AI avancé à la périphérie sans avoir besoin de matériel encombrant.
Lorsque vous comparez ces modèles, vous voyez que chacun correspond à des besoins différents. Ascend 310 et Atlas 200 fonctionnent mieux dans les petits appareils, mobiles ou extérieurs. Ascend 910C et Atlas 500 Pro vous offrent plus de puissance pour des déploiements de bord plus importants. Vous devez faire correspondre votre application AI au bon modèle pour obtenir les meilleurs résultats.
Optimisation
Modèle de compression
Vous pouvez rendre vos modèles AI plus rapides et utiliser moins de mémoire en utilisant des techniques de compression de modèle. Ces méthodes vous aident à déployer l'IA à la périphérie où les ressources sont limitées. Deux techniques populaires sont:
- Quantification: Cette méthode réduit la précision des poids du modèle. Vous obtenez des modèles plus petits et une inférence plus rapide.
- Distillation de connaissancesVous formez un modèle plus petit pour apprendre d'un modèle plus grand. Le modèle plus petit conserve de bonnes performances mais nécessite moins de ressources.
La distillation des connaissances vous permet de réduire vos modèles d'ai. Vous transférez les connaissances d'un grand modèle d'enseignant à un petit modèle d'étudiant. Ce processus vous permet d'économiser de la mémoire et d'accélérer l'inférence sur les périphériques de périphérie.
Vous devriez essayer ces techniques si vous voulez que vos applications AI fonctionnent bien sur de petits appareils.
Gestion de puissance
Vous devez gérer la puissance avec soin lorsque vous exécutez ai au bord. Les appareils comme les caméras etCapteursOnt souvent une durée de vie de la batterie limitée. Vous pouvez utiliser les modes d'économie d'énergie et planifier des tâches AI pendant les périodes de faible activité. Certains accélérateurs Ascend AI prennent en charge la mise à l'échelle dynamique de tension et de fréquence. Cette fonction vous permet d'ajuster la consommation d'énergie en fonction de la charge de travail. Vous pouvez également surveiller la température et la consommation d'énergie pour éviter la surchauffe. Une bonne gestion de l'alimentation vous aide à faire fonctionner vos systèmes AI plus longtemps et de manière plus fiable.
Conseil: La gestion intelligente de l'alimentation signifie que vos appareils AI durent plus longtemps et fonctionnent mieux dans des environnements difficiles.
Support logiciel
Vous disposez de nombreux frameworks logiciels et outils pour vous aider à déployer l'IA sur Ascend AI Accelerators. Ces outils facilitent la création, le test et l'optimisation de vos modèles.Le tableau ci-dessous montre quelques options populaires:
| Cadre/outil | Description |
|---|---|
| PyTorch (en) | Un cadre de calcul graphique dynamique idéal pour le prototypage rapide et l'expérimentation. |
| TensorFlow | Un système d'apprentissage automatique polyvalent prenant en charge plusieurs langues, largement utilisé pour diverses tâches. |
| MindSpore | Le framework open source de Huawei optimisé pour les processeurs Ascend AI, améliorant les performances grâce à la co-conception. |
| Apache MXNet | Le framework d'apprentissage en profondeur d'AWS supporte plusieurs langages de programmation. |
| Caffe | Un cadre modulaire développé pour l'extension facile de nouveaux formats de données et de couches réseau. |
| Inférence Deepytorch | Un accélérateur d'inférence pour les modèles PyTorch, améliorant les performances grâce à des techniques avancées. |
| MindStudio 2.0 | Un outil complet pour le développement de l'IA de bout en bout, simplifiant le processus pour les développeurs. |
Vous pouvez choisir le cadre qui correspond le mieux à votre projet. MindSpore fonctionne bien avec les processeurs Ascend et vous offre des performances supplémentaires. PyTorch et TensorFlow sont de bons choix si vous voulez de la flexibilité et du soutien de la communauté. MindStudio 2.0 vous aide à gérer votre développement de l'IA du début à la fin.
Liste de contrôle des décisions
Exigences Match
Vous devez vous assurer que les exigences de votre application correspondent aux fonctionnalités de l'Ascend AI Accelerator. Commencez par énumérer les besoins de votre projet. Pensez à la vitesse, la puissance, la taille, le coût et le support logiciel. Utilisez la liste de contrôle ci-dessous pour guider votre décision:
- PerformanceVotre application a-t-elle besoin d'une analyse d'image ou de vidéo rapide? Vérifiez les teraflops et la bande passante de la mémoire.
- Efficacité de puissanceVotre appareil fonctionnera sur batterie ou dans un endroit avec une puissance limitée? Recherchez les modèles à faible puissance.
- Facteur de formeVotre projet a-t-il besoin d'un petit module ou d'une station périphérique plus grande? Adaptez la taille à votre espace de déploiement.
- Coût: Pouvez-vous vous permettreMatériel et entretien? Calculez le coût total, y compris l'énergie et le soutien.
- CompatibilitéVotre logiciel fonctionnera-t-il avec des frameworks Ascend comme TensorFlow, PyTorch ou MindSpore? Assurez-vous que vos modèles fonctionnent bien.
Conseil: Notez vos trois principales exigences. Utilisez-les pour comparer chaque modèle Ascend. Cela vous aide à vous concentrer sur ce qui compte le plus pour votre projet.
| Exigence | Exemple Besoin | Ascend Feature pour correspondre |
|---|---|---|
| Vitesse | Vidéo en temps réel | TFLOPS élevé, mémoire rapide |
| Puissance | Fonctionnement sur batterie | Faible puissance en watts, puce efficace |
| Taille | Drone ou caméra | Module compact |
| Coût | Limite du budget | Faible TCO, économies d'énergie |
| Logiciel | Soutien PyTorch | Compatibilité du cadre |
Étapes de sélection
Suivez ces étapes pour choisir et déployer votre accélérateur d'Ascend AI:
- Définissez vos objectifs d'application. Écrivez ce que vous voulez que votre système d'IA fasse.
- Énumérez vos besoins techniques. Incluez vitesse, puissance, taille, coût et logiciel.
- Comparer les modèles Ascend. Utilisez votre liste de contrôle pour faire correspondre les caractéristiques de chaque modèle.
- Testez votre modèle d'IASur le matériel sélectionné. Vérifiez s'il répond à vos objectifs de vitesse et de précision.
- Examiner le pouvoir et le coût. Assurez-vous que l'appareil correspond à votre budget et à votre plan énergétique.
- Vérifier la compatibilité des logiciels. Confirmez que vos cadres et outils fonctionnent avec l'accélérateur.
- Planifier le déploiement. Décidez où et comment vous allez installer l'appareil.
- Surveiller les performances. Suivre les résultats et ajuster les paramètres pour une meilleure efficacité.
Remarque: Vous pouvez répéter ces étapes pour chaque nouveau projet. Ce processus vous aide à choisir le bon accélérateur à chaque fois.
Vous améliorez l'inférence de bord lorsque vous correspondez à vos besoins d'application avec le bon accélérateur d'Ascend AI. Vous constatez une formation plus rapide, des modèles plus simples et de meilleurs taux de détection.
| Caractéristique | Description |
|---|---|
| Temps de formation | Réduction de 75% |
| Vitesse d'inférence | Augmentation de 32,99% |
| Détection mAP | 97,1% |
Vous devriez utiliser cette liste de contrôle:
- Énumérez vos besoins de vitesse et de puissance.
- Choisissez un modèle qui correspond à votre budget.
- Vérifiez le support logiciel.
- Planifiez les futures mises à niveau.
Restez à jour à mesure que l'IA de pointe évolue. Les nouvelles tendances comme les coprocesseurs d'IA, la 5G et l'IoT ne cessent de changer ce que vous pouvez faire.
FAQ
Qu'est-ce qu'un accélérateur Ascend AI?
Vous utilisez un accélérateur Ascend AI pour accélérer les tâches d'IA. Il aide votre appareil à traiter rapidement les données. Vous obtenez de meilleures performances pour des choses comme l'analyse d'image et la surveillance vidéo.
Comment savoir quel modèle Ascend correspond à mon projet?
Vous énumérez vos besoins en termes de vitesse, de puissance, de taille et de coût. Vous comparez ces besoins aux caractéristiques de chaque modèle. Vous choisissez le modèle qui correspond le mieux à vos besoins.
Conseil: Notez vos trois principaux besoins avant de choisir.
Puis-je exécuter PyTorch ou TensorFlow sur des appareils Ascend?
Vous pouvez exécuter PyTorch et TensorFlow sur la plupart des appareils Ascend. Huawei fournit des adaptateurs et des outils open-source. VousVérifier la compatibilitéAvant de déployer vos modèles d'IA.
| Cadre | Soutenu sur Ascend? |
|---|---|
| PyTorch (en) | ✅ |
| TensorFlow | ✅ |
| MindSpore | ✅ |
Les accélérateurs d'Ascend AI fonctionnent-ils dans des environnements difficiles?
Vous pouvez utiliser certainsModèles Ascend, Comme Atlas 200, dans des conditions difficiles. Ces appareils gèrent la chaleur, le froid, les chocs et les vibrations. Vous vérifiez les spécifications de chaque modèle pour vous assurer qu'il correspond à votre environnement.
- Atlas 200: Fonctionne de-20 °C à 55 °C
- Poignées chocs et bosses



