Escolhendo o acelerador Ascend AI certo para Edge Inference
Você enfrenta muitas opções ao selecionar Ascend AI Accelerators para inferência de borda. Você deve corresponder às necessidades do seu aplicativo para

Você enfrenta muitas opções ao selecionar Ascend AI Accelerators para inferência de borda. Você deve corresponder às necessidades de desempenho, energia e custo do seu aplicativo com os recursos de hardware certos. Edge AI está crescendo rapidamente. O mercado global atingiuUS $20,78 bilhõesEm 2024 com um CAGR 21,7%. Muitas aplicações agora exigem tempos de resposta abaixo dos 50 milissegundos. A inferência ai em tempo real é importante para câmeras inteligentes, veículos e robôs. Ascend AI Accelerators trabalham com sistemas de borda e nuvem, oferecendo flexibilidade. Você vai encontrar muitos modelos. Cada uma se encaixa em diferentes tarefas, como análise de imagens, grandes modelos de linguagem ou ambientes difíceis.
| Métrica | Valor |
|---|---|
| Avaliação 2024 | US $20,78 bilhões |
| Taxa crescimento | CAGR 21,7% |
| Exigência do desempenho | Sub-50ms resposta vezes |
Dica: concentre-se no seu caso de uso e ambiente para encontrar o melhor ajuste.
Principais Takeaways
- Identifique primeiro as necessidades do seu aplicativo. Concentre-se em desempenho, potência e custo para escolher o Ascend AI Accelerator certo.
- Considere o fator de forma do acelerador. Selecione um tamanho adequado ao seu ambiente de implantação, seja compacto para drones ou maior para data centers.
- Avaliar a eficiência energética-A. Escolha aceleradores que minimizem o uso de energia para reduzir custos e prolongar a vida útil do dispositivo, especialmente para aplicações de borda.
- VerificarCompatibilidade com frameworks do software-A. Garanta que seus modelos de IA funcionem perfeitamente com ferramentas populares como TensorFlow e PyTorch para evitar problemas de integração.
- Teste seus modelos de IA no hardware selecionado. Essa etapa garante que o desempenho atenda aos requisitos de velocidade e precisão antes da implantação completa.
Ascend AI Accelerators Visão geral

Família do produto
Você pode encontrar muitas opções noLinha Ascend AI Accelerator-A. Essas plataformas ajudam você a executar tarefas ai na borda e na nuvem. CadaFamília do produtoTem um papel especial. Algumas plataformas se concentram na inferência de borda, enquanto outras suportam cargas de trabalho AI baseadas em nuvem.
| Família do produto | Função primária em Edge e Cloud Inference |
|---|---|
| Processadores Ascend AI | Camada de chip principal na pilha completa, arquitetura escalável |
| Computação Atlas AI | Fornece vários formatos do produto para infraestruturas AI |
| Módulo AI Atlas 200 | Projetado para aplicações edge |
| Atlas 300 cartão AI | Usado em ambientes cloud |
| Estação AI Atlas 500 | Metas soluções edge computing |
| Servidores Atlas 800 AI | Suporta aplicativos AI baseados em nuvem |
Você pode usar essas plataformas paraConstruir soluções ai flexíveis-A. Ascend ai aceleradores dar-lhe o poder de processar dados rapidamente. Você pode escolher as plataformas certas para suas necessidades, se você quer executar ai na borda ou na nuvem.
Integração Edge e Cloud
Os aceleradores Ascend ai funcionam bem com plataformas de borda e nuvem. Você pode implantar modelos ai em diferentes dispositivos e obter resultados rápidos. Alguns aceleradores são pequenos e se encaixam em sistemas compactos. Outros trabalham em servidores grandes para cargas pesadas ai.
Aqui estão alguns modelos e dispositivos importantes que você pode usar para inferência:
- Ascend 310: Este chip faz parte da gama Atlas. Você pode usá-lo para muitas aplicações ai.
- Atlas 200: Este compacto módulo acelerador ai oferece até16 teraflops de poder computacional-A. Ele usa apenas 8 a 13,8 watts.
- Atlas 500: Esta solução de borda fornece 16 teraflops (INT8) ou 8 teraflops (FP16). Suporta processamento em tempo real e usa 25 a 40 watts.
Você pode misturar e combinar essas plataformas para se adequar ao seu projeto. Os aceleradores Ascend AI ajudam você a construir sistemas inteligentes que respondem rapidamente. Você pode executar tarefas ai na borda para obter resultados rápidos ou enviar dados para a nuvem para uma análise mais profunda.
Nota: Você deve sempre verificar a potência e o desempenho de cada acelerador antes de escolher uma plataforma. Isso ajuda você a obter os melhores resultados para sua aplicação ai.
Inferência de IA na borda

Inferência em tempo real
Você precisa de respostas rápidas e confiáveis para muitas aplicações modernas. A inferência de IA na borda permite processar dados perto de onde eles são criados. Esta abordagem traz vários benefícios importantes:
- Processamento em tempo real: Você obtém resultados imediatos porque o dispositivo manipula dados localmente. Isso é fundamental para a inferência em tempo real em câmeras inteligentes, veículos autônomos e monitoramento de saúde.
- Privacidade e segurança: Você mantém informações confidenciais no dispositivo, o que reduz o risco de vazamentos de dados durante a transmissão.
- Eficiência de banda: você envia menos dados para a nuvem, o que economiza recursos de rede e reduz custos. Isso ajuda em áreas remotas com conectividade limitada.
- Escalabilidade: Você pode adicionar mais dispositivos de borda conforme suas necessidades crescem. Isso não sobrecarrega os seus sistemas centrais.
- Eficiência energética: os dispositivos Edge usam menos energia porque evitam a transmissão constante de dados.
- Operação offline: Sua inferência ai pode continuar funcionando mesmo que a conexão à internet caia.
Dica: a inferência ai em tempo real na borda reduz a latência. Você obtém decisões mais rápidas e melhores experiências do usuário.
Aceleração do hardware
Você pode aumentar o desempenho ai inferência comAceleração do hardware-A. Chips especiais como GPUs lidam com muitas tarefas ao mesmo tempo. Isso fazProcessamento em tempo realPossível para cargas exigentes ai. Você vê isso em ação com análise de vídeo em tempo real para segurança, manutenção preditiva em fábricas e verificações de qualidade automatizadas na fabricação.
A aceleração do hardware permite analisar dados rapidamente e tomar decisões sem esperar por servidores em nuvem. Isso reduz a latência e mantém suas informações privadas. Você também melhora o uso de energia e suporta mais cargas de trabalho em cada dispositivo. Com a otimização correta, você pode executar tarefas complexas de inferência suave e confiável.
Nota: A aceleração do hardware é fundamental para a inferência ai em tempo real. Ele ajuda você a atender a requisitos rígidos de latência e a lidar com cargas de trabalho pesadas na borda.
Critérios seleção
Escolher o acelerador Ascend AI certo para inferência de borda significa que você deve analisar vários fatores importantes. Você quer garantir que seus aplicativos de IA funcionem sem problemas e atendam às suas metas de custo, eficiência energética e desempenho. Aqui estão os principais critérios que você deve considerar:
Desempenho
Você precisa combinar o desempenho do acelerador com os seus aplicativos de AI. Algumas tarefas, como análise de imagem ou vídeo, exigem alto poder computacional. Outros, como o simplesSensorProcessamento de dados precisa menos. Você deve verificar o número de teraflops,MemóriaLargura de banda e tipos de dados suportados. A inferência rápida ajuda seus aplicativos a responder em tempo real. Se você trabalha com modelos de linguagem grandes ou cargas de trabalho complexas, precisa de um acelerador com desempenho forte. Você também deve observar o quão bem o acelerador lida com várias tarefas ao mesmo tempo.
Dica: Sempre teste seus modelos ai no hardware de destino para ver se a velocidade de inferência atende aos seus requisitos.
Eficiência energética
A eficiência energética é fundamental para implantações edge. Você quer que seus aplicativos AI funcionem por longos períodos sem superaquecer ou drenar baterias. O Ascend 910C destaca-se pela sua eficiência energética. Ele usa sobre310W, O que ajuda a reduzir o custo total de propriedade. Outros aceleradores, como o NVIDIA H100, oferecem desempenho mais bruto, mas usam muito mais energia. Você deve comparar o uso de energia de cada acelerador e escolher um que atenda às suas necessidades de implantação. Menor consumo energético significa menos calor e maior vida útil do dispositivo.
- Ascend 910C oferece forte eficiência energética para inferência borda.
- O menor uso de energia ajuda a reduzir custos e suporta aplicações sustentáveis.
- A alta eficiência energética significa que você pode implantar mais dispositivos sem aumentar seu orçamento energético.
Form Factor
O fator de forma do acelerador afeta onde você pode implantar seus aplicativos ai. Você precisa escolher um tamanho e forma que se adapte ao seu ambiente. Alguns aceleradores são pequenos e leves, perfeitos para drones ou câmeras. Outros são maiores e funcionam melhor em servidores de borda ou data centers. A tabela abaixo mostra os diferentes formatos e seu impacto na implantação:
| Form Factor | Descrição | Impacto implantação |
|---|---|---|
| Acelerador AI Atlas 200 | Módulo compacto, metade do tamanho de um cartão de crédito,10 watts potência consumo | Ideal para dispositivos como câmeras e drones, permitindo análises de vídeo HD em tempo real. |
| Atlas 300 AI acelerador | Placa padrão HHHL PCIe para data centers e servidores edge | Suporta várias precisões de dados oferecendo alto desempenho para tarefas de deep learning e inferência. |
| Estação borda AI Atlas 500 | Integra o processamento IA em um tamanho de set-top box | Apropriado para várias aplicações que incluem o transporte e os cuidados médicos, com melhorias significativas do desempenho. |
| Atlas 800 AI aparelho | Ambiente AI otimizado com software pré-instalado | Pronto para usar rapidamente, integra software de gerenciamento para aplicativos corporativos AI, reduzindo as barreiras de entrada. |
Você deve escolher um fator de forma que corresponda ao seu espaço de implantação e às necessidades de seus aplicativos AI.
Custo
O custo é um fator importante quando você seleciona um acelerador para inferência de arestas. Você precisa olhar para o preço do hardware, o custo de energia e o custo de manutenção. Alguns aceleradores custam mais antecipadamente, mas economizam dinheiro ao longo do tempo devido à melhor eficiência energética. O Ascend 910C, por exemplo, oferece boa eficiência energética, o que reduz o custo total de propriedade. Você também deve considerar o custo de licenças de software e suporte. Se você planeja escalar seus aplicativos de AI, você precisa pensar sobre o custo de adicionar mais aceleradores.
- O custo do hardware afeta seu orçamento para aplicativos AI.
- O custo energético impacta a poupança a longo prazo.
- A manutenção inclui atualizações e reparos.
- O custo total de propriedade combina todos esses fatores.
Nota: Calcule sempre o custo total antes de decidir sobre um acelerador. Isso ajuda a evitar surpresas e mantém seus aplicativos ai funcionando sem problemas.
Compatibilidade
Compatibilidade com seu hardware e software existente é essencial. Você quer que seus aplicativos ai funcionem com frameworks populares como TensorFlow e PyTorch. As plataformas Ascend suportam esses frameworks, o que facilita a integração. Huawei temCANN de código abertoPara ajudar os desenvolvedores a se afastarem dos fabricantes de chips ocidentais. O ecossistema ainda está crescendo, então você pode enfrentar alguns desafios. A Huawei também fornece adaptadores para modelos PyTorch nas NPUs Ascend. Esse foco na interoperabilidade ajuda você a alternar sem perder o suporte para seus aplicativos AI. O MindSpore oferece outra opção para construir e gerenciar cargas de trabalho.
- O Ascend suporta TensorFlow, PyTorch e MindSpore para aplicações ai.
- Ferramentas de código aberto ajudam a migrar cargas de inferência.
- A compatibilidade reduz o custo de integração e acelera a implantação.
Dica: verifique a compatibilidade de seus modelos AI e software antes de escolher um acelerador. Isso economiza tempo e custo durante a implantação.
Requisitos do aplicativo correspondente
Você deve sempre corresponder os critérios de seleção às suas aplicações ai específicas. Se você trabalha com análise de imagem ou vídeo, precisa de alto desempenho e eficiência energética. Para modelos de linguagem grandes, é preciso mais memória e poder computacional. As condições ambientais também importam. Alguns aceleradores funcionam melhor em locais difíceis ou remotos. Você deve listar seus requisitos e compará-los com os recursos de cada acelerador.
- A inferência em tempo real para câmeras e drones precisa de aceleradores compactos e eficientes em termos energéticos.
- Aplicações de saúde e transporte podem exigir maiores formatos e maior desempenho.
- O custo e a compatibilidade afetam a rapidez com que você pode implantar e dimensionar seus aplicativos AI.
Lembre-se: o melhor acelerador para sua inferência de borda depende das necessidades de sua aplicação, limites de custo, metas de eficiência energética e compatibilidade com seus sistemas existentes.
Comparação do modelo
Escolher o Ascend AI Accelerator certo para inferência de borda significa entender o que cada modelo oferece. Você quer combinar o seu aplicativo com o melhor hardware. Vamos dar uma olhada em quatro opções populares: Ascend 310, Ascend 910C, Atlas 200 e Atlas 500 Pro.
Subir 310
O Ascend 310 oferece um equilíbrio entre desempenho e eficiência. Você pode usá-lo em muitos cenários edge ai. Este chip funciona bem em dispositivos pequenos e suporta processamento em tempo real. Ele lida com até200 faces ou objetosDe uma vez, tornando-o ótimo para segurança e monitoramento.
| Usar Caso | Descrição |
|---|---|
| Câmeras segurança | Processa 200 faces ou objetos ao mesmo tempo. Perfeito para monitoramento em tempo real. |
| Drones | Aumenta recursos autônomos e suporta várias tarefas ai. |
| Varejo Autônomo Inteligente | Potencia soluções orientadas por ai no varejo, melhorando a experiência e a eficiência do cliente. |
| Monitoramento do Local Construção | Ajuda as empresas de construção a rastrear as atividades no local. |
| Monitoramento Power Line | Permite que os provedores monitorem as linhas elétricas eficientemente. |
Você pode implantar o Ascend 310 em lugares onde você precisa de inferência ai rápida, mas tem espaço ou potência limitada. Ele se encaixa bem em câmeras inteligentes, drones e sistemas de varejo.
Ascender 910C
Ascend 910C destaca-se pela sua elevada potência computacional e eficiência energética. Você se levantar para320 TFLOPS de desempenho FP16-A. Este chip usa aproximadamente 310 watts, o que é menor do que muitas GPUs concorrentes. Funciona bem para aprendizado profundo e modelos AI grandes.
| Métrica | Ascender 910C | NVIDIA B200 NVL72 |
|---|---|---|
| Consumo energético (por GPU) | 70%-80% da NVIDIA NVL72 | 100% |
| Desempenho geral do Supernode (FLOPS) | 70% maior que o NVL72 | 100% |
| Consumo energético por FLOP | 2,3 vezes maior | 1,0 |
| Consumo de energia por TB/s Memória | 1,8 vezes maior | 1,0 |
| Consumo de energia por TB Capacidade de memória HBM | 1,1 vezes maior | 1,0 |
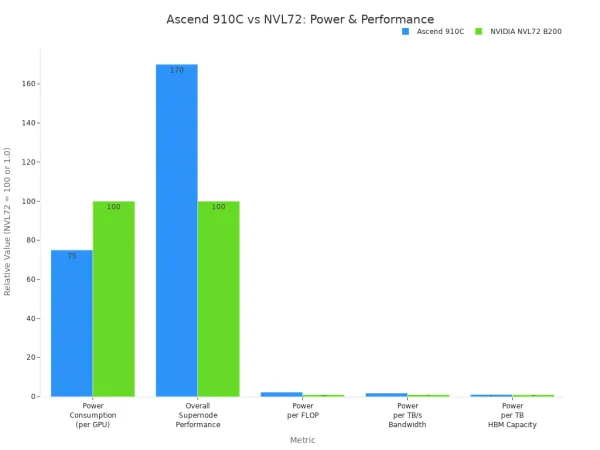
Você pode usar o Ascend 910C para exigir cargas ai. Ele se encaixa melhor em servidores de borda ou data centers onde você precisa de desempenho forte e menores custos de energia. Este modelo é ideal para treinar e executar grandes modelos AI em tempo real.
Nota: Ascend 910C compete com GPUs superiores como NVIDIA A100 e H100. Você obtém alto desempenho e economiza energia.
Atlas 200
Atlas 200 é um compacto ai módulo acelerador. É sobreMetade do tamanho do cartão de crédito-A. Você pode usá-lo em dispositivos terminais, como câmeras, robôs e drones. Este módulo suporta 16 canais de análise de vídeo HD em tempo real. Você obtém forte processamento ai em um pacote pequeno.
- Você pode implantar o Atlas 200 em câmeras para vigilância inteligente.
- Funciona bem em robôs para tomada de decisões em tempo real.
- Os drones usam o Atlas 200 para navegação e monitoramento acionados por ai.
Atlas 200 lida com ambientes difíceis. Funciona em temperaturas de-20 °C a 55 °C e pode lidar com choques e vibrações. Isso o torna uma boa escolha para aplicações ai externas ou móveis.
| Fator Ambiental | Especificação |
|---|---|
| Temperatura armazenamento | -30 do 60 °C |
| Temperatura operacional | -20 a 55 °C ambiental |
| Umidade | Funcionamento: 20% ~ 80%, relativo, sem condensação |
| Ensaio | Padrão | Parâmetros |
|---|---|---|
| Choque | EN 60068-2-27 DIN | Cada eixo (x/y/z), 20g, 11ms, /- 10 choques |
| Bump | EN 60068-2-27 DIN | Cada eixo (x/y/z), 20g, 11ms, /- 100 solavancos |
| Vibração (aleatória) | EN 60068-2-64 do RUÍDO | Cada eixo (x/y/z), 4,9g rms, 15-500Hz, aceleração 0,05g 2/Hz, 30min por eixo |
| Vibração (sinusoidal) | EN DIN 60068-2-6 | Cada eixo (x/y/z), 10-58Hz: 1,5mm, 58-500Hz: 10g, 1 oct/min, 1 hora 52 min por eixo |
Dica: Atlas 200 é uma escolha forte para ai na borda, especialmente em ambientes agressivos ou móveis.
Atlas 500 Pro
Atlas 500 Pro dá-lhe uma solução de ponta poderosa em um tamanho set-top box. Você pode usá-lo para análise de vídeo em tempo real, transporte inteligente e saúde. Este dispositivo suporta até 16 teraflops (INT8) ou 8 teraflops (FP16) de potência de computação. Ele usa entre 25 e 40 watts, tornando-o energeticamente eficiente.
Você pode implantar o Atlas 500 Pro em locais onde precisa de um desempenho forte, mas não tem espaço para servidores grandes. Ele se encaixa bem em projetos de cidades inteligentes, hospitais e centros de transporte. Você obtém inferência ai confiável e fácil integração com sistemas existentes.
Principais pontos fortes do Atlas 500 Pro:
- Oferece alto desempenho ai para aplicações edge.
- Suporta análise em tempo real para dados de vídeo e sensores.
- Funciona em ambientes onde o espaço e a energia são limitados.
Chamada: Atlas 500 Pro ajuda você a trazer a AI avançada para a borda sem a necessidade de hardware volumoso.
Quando você compara esses modelos, você vê que cada um atende a diferentes necessidades. O Ascend 310 e o Atlas 200 funcionam melhor em dispositivos pequenos, móveis ou externos. O Ascend 910C e o Atlas 500 Pro oferecem mais potência para implantações de borda maiores. Você deve combinar sua aplicação ai com o modelo certo para obter os melhores resultados.
Otimização
Modelo Compressão
Você pode fazer seus modelos ai rodar mais rápido e usar menos memória usando técnicas de compactação de modelos. Esses métodos ajudam você a implantar ai na borda onde os recursos são limitados. Duas técnicas populares são:
- Quantização: Este método reduz a precisão dos pesos do modelo. Você tem modelos menores e inferência mais rápida.
- Conhecimento Destilação: Você treina um modelo menor para aprender com um maior. O modelo menor mantém bom desempenho, mas requer menos recursos.
A destilação do conhecimento permite que você encolha seus modelos ai. Você transfere conhecimento de um modelo grande professor para um modelo pequeno aluno. Esse processo ajuda você a economizar memória e acelerar a inferência em dispositivos de borda.
Você deve tentar essas técnicas se quiser que seus aplicativos AI funcionem bem em dispositivos pequenos.
Gestão Energia
Você precisa gerenciar o poder com cuidado quando você executar ai na borda. Dispositivos como câmeras eSensoresMuitas vezes têm vida útil limitada da bateria. Você pode usar modos de economia de energia e agendar tarefas ai durante períodos de baixa atividade. Alguns aceleradores Ascend AI suportam tensão dinâmica e escala de frequência. Esse recurso permite ajustar o uso de energia com base na carga. Você também pode monitorar a temperatura e o uso de energia para evitar superaquecimento. O bom gerenciamento de energia ajuda você a manter seus sistemas AI funcionando mais e mais confiável.
Dica: o gerenciamento inteligente de energia significa que seus dispositivos AI duram mais e funcionam melhor em ambientes difíceis.
Suporte Software
Você tem muitas estruturas de software e ferramentas para ajudá-lo a implantar AI no Ascend AI Accelerators. Essas ferramentas facilitam a criação, o teste e a otimização de seus modelos.A tabela abaixo mostra algumas opções populares:
| Quadro/Ferramenta | Descrição |
|---|---|
| PyTorch | Um quadro gráfico computacional dinâmico ideal para prototipagem rápida e experimentação. |
| TensorFlow | Um sistema de aprendizado de máquina versátil que suporta vários idiomas, amplamente utilizado para várias tarefas. |
| MindSpore | A estrutura de código aberto da Huawei otimizada para processadores Ascend AI, aprimorando o desempenho por meio do co-design. |
| MXNet Apache | A estrutura deep learning da AWS suporta várias linguagens de programação. |
| Caffe | Uma estrutura modular desenvolvida para facilitar a extensão de novos formatos de dados. |
| Inferência Deepytorch | Acelerador de inferência para modelos PyTorch, melhorando o desempenho com técnicas avançadas. |
| MindStudio 2.0 | Uma ferramenta abrangente para o desenvolvimento de IA de ponta a ponta, simplificando o processo para os desenvolvedores. |
Você pode escolher a estrutura que melhor se adapta ao seu projeto. O MindSpore funciona bem com processadores Ascend e oferece um desempenho extra. PyTorch e TensorFlow são boas escolhas se você quiser flexibilidade e suporte comunitário. O MindStudio 2.0 ajuda você a gerenciar seu desenvolvimento ai do início ao fim.
Decisão Checklist
Requisitos Correspondência
Você precisa garantir que os requisitos do seu aplicativo se encaixem nos recursos do Ascend AI Accelerator. Comece listando o que seu projeto precisa. Pense em velocidade, potência, tamanho, custo e suporte de software. Use a lista abaixo para orientar sua decisão:
- Desempenho: Sua aplicação precisa a análise rápida da imagem ou do vídeo? Verifique os teraflops e a memória.
- Eficiência energética: O seu dispositivo funciona com bateria ou em um local com energia limitada? Procure modelos de baixa potência.
- Form Factor: Seu projeto precisa um módulo pequeno ou uma estação de borda maior? Corresponda o tamanho ao espaço de implantação.
- Custo: Você pode pagar oHardware e manutenção? Calcule o custo total, incluindo energia e suporte.
- Compatibilidade: O seu software funcionará com frameworks Ascend como TensorFlow, PyTorch ou MindSpore? Verifique se seus modelos funcionam sem problemas.
Dica: annote os três principais requisitos. Use-os para comparar cada modelo Ascend. Isso ajuda você a se concentrar no que mais importa para o seu projeto.
| Requisitos | Exemplo Necessidade | Ascender Recurso para Match |
|---|---|---|
| Velocidade | Vídeo em tempo real | TFLOPS altos, memória rápida |
| Energia | Operação a bateria | Baixa potência, chip eficiente |
| Tamanho | Drone ou câmera | Módulo compacto |
| Custo | Limite orçamental | Baixo TCO, economia energética |
| Software | Suporte PyTorch | Compatibilidade do quadro |
Seleção Passos
Siga estas etapas para escolher e implantar seu Ascend AI Accelerator:
- Defina os objetivos do seu aplicativo-A. Anote o que você quer que seu sistema de IA faça.
- Liste suas necessidades técnicas-A. Inclua velocidade, potência, tamanho, custo e software.
- Compare os modelos Ascend-A. Use sua lista para corresponder aos recursos de cada modelo.
- Teste seu modelo AISobre o hardware selecionado. Verifique se ele atende às metas de velocidade e precisão.
- Revise o poder e o custo-A. Verifique se o dispositivo se adapta ao seu orçamento e plano energético.
- Verifique a compatibilidade do software-A. Confirme que seus frameworks e ferramentas funcionam com o acelerador.
- Planeje a implantação-A. Decida onde e como você irá instalar o dispositivo.
- Monitore o desempenho-A. Acompanhe os resultados e ajuste as configurações para melhor eficiência.
Observação: Você pode repetir essas etapas para cada novo projeto. Esse processo ajuda você a escolher o acelerador certo todas as vezes.
Você melhora a inferência de borda quando corresponde às necessidades do seu aplicativo com o Ascend AI Accelerator correto. Você vê treinamento mais rápido, modelos mais simples e melhores taxas de detecção.
| Característica | Descrição |
|---|---|
| Tempo treinamento | 75% redução |
| Velocidade Inferência | 32,99% aumento |
| Detecção mAP | 97,1% |
Você deve usar este checklist:
- Liste suas necessidades de velocidade e potência.
- Escolha um modelo adequado ao seu orçamento.
- Verifique o suporte do software.
- Planeje para atualizações futuras.
Fique atualizado conforme a Edge AI evolui. Novas tendências como co-processadores de IA, 5G e IoT continuam mudando o que você pode fazer.
FAQ
O que é um Ascend AI Accelerator?
Você usa um Ascend AI Accelerator para acelerar tarefas AI. Ele ajuda seu dispositivo a processar dados rapidamente. Você obtém melhor desempenho para coisas como análise de imagens e monitoramento.
Como sei qual modelo Ascend se encaixa no meu projeto?
Você lista suas necessidades de velocidade, potência, tamanho e custo. Você compara essas necessidades com os recursos de cada modelo. Você escolhe o modelo que melhor corresponde às suas necessidades.
Dica: Anote suas três principais necessidades antes de escolher.
Posso executar o PyTorch ou o TensorFlow em dispositivos Ascend?
Você pode executar PyTorch e TensorFlow na maioria dos dispositivos Ascend. A Huawei fornece adaptadores e ferramentas de código aberto. VocêVerificar compatibilidadeAntes de implantar modelos de IA.
| Enquadramento | Apoiado em Ascend? |
|---|---|
| PyTorch | ✅ |
| TensorFlow | ✅ |
| MindSpore | ✅ |
Os aceleradores Ascend AI funcionam em ambientes agressivos?
Você pode usar algunsModelos Ascend, Como Atlas 200, em condições difíceis. Esses dispositivos lidam com calor, frio, choque e vibração. Você verifica as especificações de cada modelo para garantir que ele se adapte ao seu ambiente.
- Atlas 200: Trabalhos de-20 °C a 55 °C
- Alças choques e solavancos