

Обработка ИИ в реальном времени Почему задержка является ключевой для HiSilicon
Для HiSilicon AI SoC низкая задержка является наиболее важным показателем производительности. Это оборудование сосредоточено на производительности с низкой задержкой e

Для HiSilicon AI SoC низкая задержка является наиболее важным показателем производительности. Этот аппаратный фокус на производительности с низкой задержкой позволяет обрабатывать данные в реальном времени. Рост рынка ИИ до прогнозируемого$143 млрд к 2034 годуПодчеркивает спрос на эту производительность оборудования. В системах, где важна задержка,Задержка более 100 миллисекунд ухудшает показатели безопасности. Специализированная аппаратная архитектура HiSilicon отдает приоритет этой сквозной производительности с задержкой. Такая аппаратная конструкция обеспечивает превосходную производительность ИИ в реальном мире.Raw TOPS не отражает истинную производительность оборудования. Эта аппаратная ориентация на производительность с задержкой является ключом к производительности оборудования AI, поскольку само оборудование является ядром производительности оборудования AI.
Ключевые выходы
- Низкая задержка очень важна для чипов ИИ HiSilicon. Это означаетЧипБыстро принимает решения, что является ключевым для задач в реальном времени.
- Специальная конструкция HiSilicon, называемая NPU Da Vinci, помогает моделям ИИ работать быстро. Он использует уникальный 3D куб для быстрого математического вычисления.
- Специальные части вЧип, Как и процессор сигналов изображения, помогает основной части ИИ. Они делают всю систему быстрее, выполняя конкретные работы.
- Быстрая обработка ИИ помогает беспилотным автомобилям, умным городам и интеллектуальным устройствам. Это делает их более безопасными и лучше работать в реальной жизни.
ПОЧЕМУ ВОПРОСЫ ПОСЛЕ В EDGE AI

В приложениях Edge AI каждая миллисекунда на счету. Система должна обрабатывать потоки данных в реальном времени, где отставание может привести к пропущенным событиям или неправильным действиям. Вот почему латентность имеет значение. Алгоритмы управления зависят от немедленных решений вывода для поддержания стабильности и безопасности. Задержка может поставить под угрозу производительность всей системы.Истинная производительность оборудования-это не только вычислительная мощность; речь идет о скорости конечного, действенных выходных данных.
ОПРЕДЕЛЕНИЕ ЛАТЕНТНОСТИ ОБРАБОТКИ AI
Профессионалы формально определяют задержку вывода ИИ как время, необходимое модели ИИ для получения входных данных и возврата прогноза. Это измерение обычно выражается в миллисекундах (мс).Тем не менее, сквозная задержка дает более полную картину производительности системы. Он охватывает весь путь от сбора данных до окончательного действия.
Эта общая задержка включает несколько отдельных этапов:
- Заглатывание данных и предварительная обработка: Аппаратное обеспечение сначала готовит входные данные. Этот шаг включает в себя форматирование и проверку данных до того, как они достигнут моделей ИИ.
- Модель вывода: Это время вычислений ядра. Аппаратное обеспечение запускает модели ИИ для генерации прогноза на основе входных данных. Производительность вывода здесь имеет решающее значение.
- Пост-обработка и выход: Оборудование форматирует вывод модели. Он готовит результат для следующего компонента системы, такого как контроллер роботизированной руки или дисплей.
Примечание:Для интерактивного ИИ другие показатели также подчеркивают производительность оборудования.Время до первого токена (TTFT)Измеряет, как быстро пользователь получает первую часть ответа, что жизненно важно для бесперебойного взаимодействия с пользователем.
ОГРАНИЧЕНИЯ ОБЩЕГО-ЦЕЛЕВОГО CPUS
Процпроцессоры общего назначения не созданы для требований современного ИИ.Процпроцессоры используют небольшое количество мощных ядер, обычно от 4 до 64. Эта архитектура превосходит сложные, последовательные задачи. Тем не менее, модели ИИ требуют массивно параллельных вычислений, выполняющих тысячи простых операций одновременно. Это несоответствие создает значительное узкое место производительности.Конструкция процессора ограничивает его производительность вывода для параллельных рабочих нагрузок.
Даже в системах с мощным графическим процессором процессор может ограничивать общую производительность, особенно в приложениях, чувствительных к задержкам.Процессор изо всех сил пытается подавать данные в ускоритель достаточно быстро, что вредит производительности вывода системы. Вот почемуСпециализированное оборудованиеНеобходим для оптимальной производительности ИИ.
Тесты четко показывают разрыв в производительности между процессорами и специализированным оборудованием, таким какНейронные блоки обработки(НПУ). Для обычных моделей ИИ, таких как YOLOv3, NPU обеспечивают гораздо лучшую производительность вывода.
| Тип системы | Снижение относительной задержки |
|---|---|
| Система только для ЦП | Исходный показатель |
| Система с питанием от НПУ | ~ 1,6x быстрее |
Эти данные показывают, что выделенное оборудование значительно сокращает время, необходимое для запуска моделей ИИ. Архитектурное преимущество NPU напрямую выражается в более низкой задержке и превосходной производительности вывода. На приведенной ниже диаграмме показано, как различные специализированные аппаратные платформы достигают различной задержки для популярных моделей ИИ.
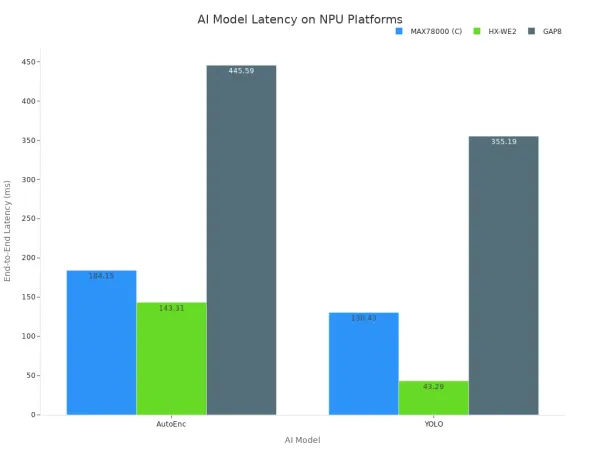
В конечном счете, использование процессоров для задач ИИ в реальном времени ставит под угрозу отзывчивость системы. Аппаратное обеспечение просто не предназначено для работы. Достижение низкой задержки, которая имеет значение, требует аппаратного обеспечения, специально предназначенного для моделей ИИ, обеспечения производительности и надежности вывода высшего уровня.
АРХИТЕКТУРА HISILICON ДЛЯ НИЗКОГО ПОСЛЕДСТВИЯ

HiSilicon достигает своей ведущей в отрасли производительности с низкой задержкой благодаря целостной аппаратной архитектуре. Эта конструкция выходит за рамки одного мощного процессора. Он объединяет специализированные вычислительные ядра, высокоскоростнойПамятьСистема и специализированные аппаратные ускорители. Эта комбинация гарантирует, что данные перемещаются и обрабатываются с максимальной эффективностью, что очень важно для приложений ИИ в реальном времени. Общая производительность системы зависит от этой тесной интеграции.
ЯДРО ДА ВИНЧИ НПУ
Блок нейронной обработки Da Vinci (NPU) является сердцем искусственного интеллекта HiSilicon. Этот NPU-мощный ускоритель ИИ, разработанный специально для математических операций, которыеСовременные модели ИИ. Его архитектура не является однородной; он сочетает в себе различные типы вычислительных единиц для оптимизации производительности. ЭтотРазнородный дизайнЯвляется ключевой причиной его отличных результатов вывода.
Ядро содержит три основных компонента, работающих вместе:
- Скалярные единицы: Они обрабатывают общую логику и поток управления для моделей ИИ.
- Векторные единицы: Они отлично подходят для выполнения многих простых операций одновременно, что является общей необходимостью для определенных уровней в моделях ИИ.
- Блоки куба 3Д: Это самый важный компонент для ускорения ИИ. Эти единицы созданы для выполнения умножения матриц с невероятной скоростью.
Эта структура позволяет ядру Da Vinci обрабатывать сложные модели ИИ с минимальной задержкой. Кубические юниты справляются с тяжелым поднятием матричной математики, в то время как векторные и скалярные юниты управляют окружающими задачами. Такое разделение труда внутри ускорителя ИИ гарантирует, что ни одна часть оборудования не создает узкое место. Результатом является превосходная производительность вывода и более низкая задержка для требовательных рабочих нагрузок ИИ. Эти ускорители ИИ имеют основополагающее значение для общей производительности системы.
ПАМЯТЬ ON-ЧИПА И МЕЖСОЕДИНЕКТЫ
Быстрый NPU требует быстрых данных. Если ускоритель ИИ должен ждать данных, его преимущество в производительности теряется. Аппаратный дизайн HiSilicon решает эту проблему с помощью сложной иерархии встроенной памяти и высокоскоростных межсоединений. Эти компоненты создают супермагистраль данных, минимизируя задержку, связанную с перемещением информации по чипу. Этот эффективный поток данных имеет решающее значение для производительности вывода оборудования.
HiSilicon SoC используют расширенные межсоединения для связи NPU, процессора и памяти. Это гарантирует, что все компоненты могут обмениваться данными с минимальной задержкой. Выбор технологии памяти также играет жизненно важную роль в производительности системы.
| Модель чипа | Интерконнект | Технология памяти |
|---|---|---|
| Кирин 960 | ARM CCI-550 | LPDDR4-1600 (64-битный двухканальный) |
| Кирин 970 | ARM CCI-550 | LPDDR4 |
Помимо основной памяти, система использует несколько уровней встроенной памяти (кэшей). Сам NPU да Винчи содержит свою собственную локальную память. Это позволяет ускорителю AI хранить часто используемые данные для моделей AI рядом с вычислительные блоки, резко сокращая задержку доступа к данным. Эта архитектура также повышает энергоэффективность.Эффективный встроенный поток данных, часто управляемый сетью на чипе (NoC), снижает энергопотребление за счет отправки данных в виде гибких пакетов. Такой подход снижает количество физических проводов и повышает производительность.Другие методы еще больше повышают эту эффективность:
- Мелкозернистые решетчатая решетка: Этот метод использует стробоскопы для регулирования потока данных между аппаратными блоками.
- БуферизацияЯвные буферы (FIFO) гарантируют, что данные доступны именно тогда, когда они нужны ускорителю ИИ, предотвращая остановку и трату энергии.
ВЫДЕЛЕННОЕ УСКОРЕНИЕ ОБОРУДОВАНИЯ
NPU-звездный игрок, но это не единственный аппаратный ускоритель в команде. HiSilicon SoC объединяет набор специализированных аппаратных ускорителей, которые обрабатывают конкретные задачи. Эти ускорители разгружают работу от CPU и NPU, уменьшая сквозную задержку всего конвейера AI. Этот подход жизненно важен для сложных задач, таких как анализ видео в реальном времени, и обеспечивает эффективный вывод на устройстве.
В приложениях компьютерного зрения,Сигнальный процессор изображения (ISP)Является важнейшим аппаратным ускорителем. ISP работает напрямую с NPU, чтобы обеспечить лучшую производительность вывода.
- ISP обрабатывает начальные задачи обработки изображений, такие как слияние High Dynamic Range (HDR) и расширенное шумоподавление.
- Он подготавливает и оптимизирует видеоданные специально для моделей ИИ, работающих на NPU.
- Эта предварительная обработка специальным аппаратным ускорителем означает, что NPU получает чистые, готовые к анализу данные, что ускоряет конечный результат ИИ.
Точно так же аппаратные видеокодеры и декодеры являются важными ускорителями ИИ для анализа видеопотоков с высоким разрешением. Эти ускорители управляют всем конвейер обработки видео на одном чипе.
- Они декодирует входящие видеопотоки, не нагружая процессор.
- Они позволяют NPU анализировать видео локально.
- Они передают только критические данные о событиях, что резко снижает пропускную способность сети и затраты на хранение.
Эта команда специализированных аппаратных ускорителей гарантирует, что каждый этап задачи ИИ, от сбора данных до конечного вывода, оптимизирован для скорости. Этот комплексный подход к аппаратному проектированию-это то, что дает HiSilicon преимущество в производительности с низкой задержкой для ИИ в реальном времени. Синергия между этими ускорителями обеспечивает уровень производительности, который не может соответствовать одному процессору.
РЕАЛЬНО-МИРОВЫЕ НИЗКИЕ ПРИЛОЖЕНИЯ
Аппаратное обеспечение с низкой задержкой открывает интеллектуальные системы нового поколения. Производительность этих систем зависит от немедленной обработки данных. Аппаратная архитектура HiSilicon обеспечивает скорость, необходимую для критически важных приложений ИИ в реальном мире. Превосходная производительность моделей ИИ позволяет мгновенно принимать решения там, где миллисекунды имеют значение.
АВТОНОМНЫЕ СИСТЕМЫ
В автономных системах низкая задержка является не подлежащим обсуждению требованием для безопасности и точности. Оборудование должно обрабатыватьДатчикДанных и выполнять модели ИИ с минимальной задержкой для обеспечения надежной работы.
- Автономные автомобили: Для самостоятельного вождения автомобиля для обнаружения пешехода и приведения в действие тормозов требуетсяСквозная задержка от 50 до 100 миллисекунд. Любая задержка за пределами этого ставит под угрозу безопасность. Аппаратное обеспечение автомобиля должно последовательно обеспечивать эту производительность.
- Промышленная робототехника: НаСборкаРоботы нуждаются в быстрой обратной связи для выполнения точных задач.Sub-100ms циклы выполненияДля моделей с ИИ позволяютУлучшенный контроль качества и повышенная безопасность работников. Эта производительность оборудования с низкой задержкой напрямую повышает производительность производства.
УМНАЯ ИНФРАСТРУКТУРА
Умные города и заводы используют анализ ИИ на камере для повышения эффективности и безопасности. Это требует мощного краевого оборудования, способного обрабатывать видеопотоки в реальном времени. Эффективность этих моделей ИИ является ключом к их успеху.
Обнаружение угроз в реальном времени:В умных городах камеры ИИ контролируют общественные места. Оборудование анализирует видеопотоки наВыявлять нарушения правил дорожного движения, оставленные объекты или другие потенциальные угрозы, позволяющие немедленно реагировать. Эта производительность ИИ помогает правоохранительным органам и оптимизирует аварийно-спасательные службы..
На умных фабриках,Системы искусственного зрения обеспечивают мгновенный контроль качества. Оборудование запускает модели осмотра которые анализируют продукты на сборочной линии,Выявление дефектов, таких как царапины или несоответствия. Эта немедленная обратная связь улучшает качество продукции без замедления производства. Производительность моделей ИИ имеет решающее значение здесь.
УМНЫЕ УСТРОЙСТВА И МЕДИА
Обработка ИИ с низкой задержкой улучшает пользовательский опыт в бытовой электронике и медицинских устройствах. Аппаратное обеспечение обеспечивает сложные функции, которые работают непосредственно на устройстве.
Умные телевизоры используютМодели AI для масштабирования видео 8K в реальном времени. Аппаратный AI-процессор анализирует контент покадрово, чтобы улучшить детали и уменьшить шум., Обеспечивая превосходное изображение. Эта производительность высокого уровня происходит мгновенно. Для телемедицины и носимых устройств,Аппаратное обеспечение на устройствеАнализирует биометрические данные.Модели обнаружения аварийных событий требуют задержки менее 50 мсДля оповещения пользователей или медицинского персонала. Эта быстрая производительность ИИ может спасти жизнь.
Для краевой ИИ в реальном времени имеет значение сквозная задержка.Сырая вычислительная пропускная способность сама по себе не определяет истинную производительность оборудования. Аппаратная архитектура HiSilicon с его NPU Da Vinci и выделенными аппаратными ускорителями обеспечивает эту критическую производительность с низкой задержкой. Производительность этих аппаратных ускорителей является ключевой. Аппаратные ускорители обеспечивают отличную производительность.
Примечание для разработчиков:Вы должны сравнить оборудование с задержкой. Это гарантирует реальную производительность и надежность оборудования. Задержка имеет значение для производительности этого оборудования. Аппаратные ускорители и аппаратное обеспечение обеспечивают эту производительность. Производительность аппаратных ускорителей имеет жизненно важное значение. Производительность оборудования зависит от этих аппаратных ускорителей.
Часто задаваемые вопросы
Почему задержка важнее, чем TOPS для edge AI?
TOPS измеряет сырую вычислительные мощности. Задержка измеряет общее время для принятия решения. Для приложений реального времени, таких как автономное вождение, быстрое решение более важно для безопасности и производительности, чем просто высокая вычислительная производительность.
Низкая задержка гарантирует, что система может мгновенно реагировать на новую информацию.
Что такое NPU да Винчи?
NPU Da Vinci-специализированный ИИ-акселератор HiSilicon. Он использует уникальную архитектуру 3D Cube для матричной математики. Такая конструкция значительно ускоряет вычисления моделей ИИ. Это напрямую снижает задержку вывода и повышает общую производительность системы для задач в реальном времени.
Как аппаратные ускорители повышают производительность ИИ?
Аппаратные ускорители, такие как процессор сигналов изображения (ISP), выполняют определенные задания. Они выгружают задачи из главного процессора. Эта параллельная обработка уменьшает узкие места. Весь конвейер AI работает быстрее, снижая сквозную задержку и обеспечивая эффективный вывод на устройстве.
Какие приложения требуют сверхнизкой задержки?
Приложения, требующие немедленного действия, требуют низкой задержки. Эти системы зависят от быстрого принятия решений в режиме реального времени. Ключевые примеры включают:
- Автономные системы (транспортные средства, робототехника)🤖
- Умная инфраструктура (обнаружение угроз)🏙️
- Расширенные медиа (масштабирование 8K)📺
- Телемедицина (экстренные оповещения)❤️🩹





