

Echtzeit-KI-Verarbeitung Warum Latenz für HiSilicon der Schlüssel ist
Für HiSilicon AI-SoCs ist eine niedrige Latenz die kritisch ste Leistungs metrik. Diese Hardware konzentrieren sich auf niedrige Latenz Leistung e

Für HiSilicon AI-SoCs ist eine niedrige Latenz die kritisch ste Leistungs metrik. Dieser Hardware-Fokus auf Leistung mit geringer Latenz ermöglicht die Datenverarbeitung in Echtzeit. Das Wachstum des KI-Marktes auf ein projiziertes143 Milliarden US-Dollar bis 2034Hebt die Nachfrage nach dieser Hardware-Leistung hervor. In Systemen, in denen Latenz wichtig ist,Eine Verzögerung über 100 Millisekunden verschl echtert die Sicherheits leistung. Die spezial isierte Hardware architektur von HiSilicon priorisiert diese End-to-End-Latenz leistung. Dieses Hardware-Design gewähr leistet eine überlegene KI-Leistung in der realen Welt.Raw TOPS spiegelt nicht die tatsächliche Hardware leistung wider. Dieser Hardware fokus auf die Latenz leistung ist der Schlüssel für die KI-Hardware leistung, da die Hardware selbst der Kern der KI-Hardware leistung ist.
Wichtige Imbiss buden
- Eine geringe Latenz ist für die KI-Chips von HiSilicon sehr wichtig. Es bedeutet, dass dieChipTrifft Entscheidungen schnell, was für Echtzeit aufgaben von entscheidender Bedeutung ist.
- Das spezielle Design von HiSilicon, das als Da Vinci NPU bezeichnet wird, hilft KI-Modellen, schnell zu arbeiten. Es verwendet einen einzigartigen 3D-Würfel, um schnell zu rechnen.
- Sonderteile in derChipWie der Bildsignal prozessor helfen Sie dem KI-Hauptteil. Sie machen das gesamte System schneller, indem sie bestimmte Aufgaben erledigen.
- Schnelle KI-Verarbeitung hilft selbst fahrenden Autos, Smart Cities und intelligenten Geräten. Es macht sie sicherer und arbeitet besser im wirklichen Leben.
WARUM LATENZ ANGELEGENHEITEN IN EDGE AI

In Edge-KI-Anwendungen zählt jede Millisekunde. Das System muss Datenströme in Echtzeit verarbeiten, bei denen ein Rückstand zu verpassten Ereignissen oder falschen Aktionen führen kann. Deshalb ist Latenz wichtig. Kontroll algorithmen hängen von sofortigen Inferenz entscheidungen ab, um Stabilität und Sicherheit aufrecht zu erhalten. Eine Verzögerung kann die Leistung des gesamten Systems beeinträchtigen.Bei der echten Hardware leistung geht es nicht nur um Rechen leistung. Es geht um die Geschwindigkeit der endgültigen, umsetzbaren Ausgabe.
DEFINIERUNG DER KI-VERARBEITUNG LATENZ
Fachleute definieren die KI-Inferenz latenz formal als die Zeit, die ein KI-Modell benötigt, um eine Eingabe zu erhalten und eine Vorhersage zurück zugeben. Diese Messung wird typischer weise in Millisekunden (ms) ausgedrückt.Die End-to-End-Latenz bietet jedoch ein vollständige res Bild der System leistung. Es deckt die gesamte Reise von der Daten erfassung bis zur endgültigen Aktion ab.
Diese Gesamt latenz umfasst mehrere unterschied liche Stufen:
- Daten aufnahme und Vor verarbeitung: Die Hardware bereitet zunächst Eingabedaten auf. Dieser Schritt beinhaltet das Formatieren und Validieren der Daten, bevor sie die KI-Modelle erreichen.
- Modell Inferenz: Dies ist die Kern berechnungs zeit. Die Hardware führt die KI-Modelle aus, um eine Vorhersage basierend auf den Eingabedaten zu generieren. Die Inferenz leistung ist hier kritisch.
- Nach bearbeitung und Ausgabe: Die Hardware formatiert die Ausgabe des Modells. Es bereitet das Ergebnis für die nächste System komponente vor, wie zum Beispiel eine Roboterarm steuerung oder ein Display.
Anmerkung:Für interaktive KI unterstreichen andere Metriken auch die Hardware leistung.Zeit zum ersten Token (TTFT)Misst, wie schnell ein Benutzer die erste Antwort erhält, was für eine reibungslose Benutzer erfahrung von entscheidender Bedeutung ist.
EINSCHRÄNKUNGEN DES ALLGEMEINEN ZWECK-CPUS
Allzweck-CPUs sind nicht für die Anforderungen der modernen KI gebaut.CPUs verwenden eine kleine Anzahl leistungs starker Kerne, normaler weise zwischen 4 und 64. Diese Architektur zeichnet sich durch komplexe, sequentielle Aufgaben aus. KI-Modelle erfordern jedoch massiv parallele Berechnungen, bei denen Tausende von einfachen Operationen gleichzeitig ausgeführt werden. Diese Nicht übereinstimmung führt zu einem erheblichen Leistungs engpass.Das Design der CPU begrenzt die Inferenz leistung für parallele Arbeitslasten.
Selbst in Systemen mit einer leistungs starken GPU kann die CPU die Gesamt leistung einschränken, insbesondere in latenz sensitiven Anwendungen.Die CPU hat Schwierigkeiten, Daten schnell genug an den Beschleuniger weiter zuführen, was die Inferenz leistung des Systems beeint rächt igt. DeshalbSpezial isierte HardwareIst für eine optimale KI-Leistung notwendig.
Benchmarks zeigen deutlich die Leistungs lücke zwischen CPUs und spezial isierter Hardware wieNeuronale Verarbeitung einheiten(NPUs). Für gängige KI-Modelle wie YOLOv3 bieten NPUs eine weitaus bessere Inferenz leistung.
| System typ | Relative Latenz reduktion |
|---|---|
| Nur CPU-System | Baseline |
| NPU-betriebenes System | ~ 1,6 x Schneller |
Diese Daten zeigen, dass dedizierte Hardware die Zeit für die Ausführung von KI-Modellen erheblich reduziert. Der architekto nische Vorteil von NPUs führt direkt zu einer geringeren Latenz und einer überlegenen Inferenz leistung. Die folgende Tabelle zeigt weiter, wie verschiedene spezial isierte Hardware plattformen eine unterschied liche Latenz für beliebte KI-Modelle erreichen.
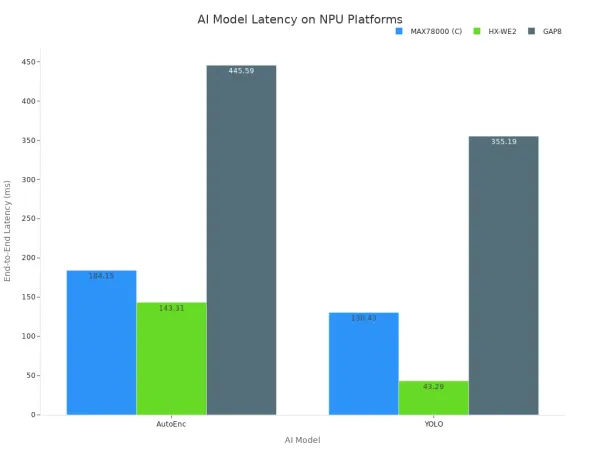
Letztendlich beeint rächt igt das Verlassen von CPUs für Echtzeit-KI-Aufgaben die Reaktions fähigkeit des Systems. Die Hardware ist einfach nicht für den Job ausgelegt. Um die niedrige Latenz zu erreichen, die wichtig ist, ist Hardware erforderlich, die speziell für KI-Modelle entwickelt wurde, um sicher zustellen, dass erstklassige Inferenz leistung und Zuverlässigkeit gewähr leistet sind.
HISILIKONS ARCHITEKTUR FÜR NIEDRIGE LATENZ

HiSilicon erreicht seine branchen führende Leistung mit geringer Latenz durch eine ganzheitliche Hardware architektur. Dieses Design geht über einen einzigen leistungs starken Prozessor hinaus. Es integriert spezial isierte Rechen kerne, eine High-SpeedErinnerungSystem und dedizierte Hardware-Beschleuniger. Diese Kombination stellt sicher, dass Daten mit maximaler Effizienz verschoben und verarbeitet werden, was für Echtzeit-KI-Anwendungen unerlässlich ist. Die Gesamtsystem leistung hängt von dieser engen Integration ab.
DER DA VINCI NPU KERN
Die Da Vinci Neural Processing Unit (NPU) ist das Herzstück der KI-Hardware von HiSilicon. Diese NPU ist ein leistungs starker KI-Beschleuniger, der speziell für die mathematischen Operationen entwickelt wurde, die MachtModerne KI-Modelle. Seine Architektur ist nicht einheitlich; Es werden verschiedene Arten von Rechen einheiten kombiniert, um die Leistung zu optimieren. DieseHeterogenes DesignIst ein Hauptgrund für seine hervorragende Inferenz leistung.
Der Kern enthält drei Haupt komponenten, die zusammenarbeiten:
- Skalar-Einheiten: Diese behandeln den allgemeinen Logik-und Kontroll fluss für die KI-Modelle.
- Vektor-Einheiten: Diese können viele einfache Operationen gleichzeitig ausführen, was für bestimmte Schichten in KI-Modellen häufig erforderlich ist.
- 3D Würfel Einheiten: Dies ist die kritisch ste Komponente für die KI-Beschleunigung. Diese Einheiten sind so gebaut, dass sie eine Matrix multi pli kation mit unglaublichen Geschwindigkeiten durchführen.
Diese Struktur ermöglicht es dem Da Vinci-Kern, komplexe KI-Modelle mit minimaler Verzögerung zu verarbeiten. Die Würfel einheiten übernehmen das schwere Heben der Matrix mathematik, während die Vektor-und Skalare inheiten die umgebenden Aufgaben verwalten. Diese Arbeits teilung innerhalb des KI-Beschleunigers sorgt dafür, dass kein einzelner Teil der Hardware einen Engpass erzeugt. Das Ergebnis ist eine überlegene Inferenz leistung und eine geringere Latenz für anspruchs volle KI-Workloads. Diese KI-Beschleuniger sind für die Gesamt leistung des Systems von grundlegender Bedeutung.
ON-CHIP-SPEICHER UND INTERCONNECTS
Eine schnelle NPU braucht schnelle Daten. Wenn der KI-Beschleuniger auf Daten warten muss, geht sein Leistungs vorteil verloren. Das Hardware-Design von HiSilicon begegnet dieser Herausforderung mit einer ausgeklü gelten On-Chip-Speicher hierarchie und Hoch geschwindigkeit verbindungen. Diese Komponenten erstellen eine Daten autobahn, die die Latenz minimiert, die mit dem Verschieben von Informationen um den Chip verbunden ist. Dieser effiziente Datenfluss ist entscheidend für die Inferenz leistung der Hardware.
HiSilicon-SoCs verwenden erweiterte Verbindungen, um NPU, CPU und Speicher zu verbinden. Dies stellt sicher, dass alle Komponenten mit minimaler Verzögerung kommunizieren können. Die Wahl der Speichert echno logie spielt auch eine wichtige Rolle für die System leistung.
| Chip-Modell | Verbinden | Speichert echno logie |
|---|---|---|
| Kirin 960 | ARM-CCI-550 | LPDDR4-1600 (64-Bit-Dual-Channel) |
| Kirin 970 | ARM-CCI-550 | LPDDR4 |
Über den Haupt speicher hinaus verwendet das System mehrere Ebenen des On-Chip-Speichers (Caches). Die Da Vinci NPU selbst enthält einen eigenen lokalen Speicher. Dies ermöglicht es dem KI-Beschleuniger, häufig verwendete Daten für KI-Modelle direkt neben den Rechen einheiten zu speichern, wodurch die Latenz des Datenzugriffs drastisch verringert wird. Diese Architektur verbessert auch die Energie effizienz.Ein effizienter On-Chip-Datenfluss, der häufig von einem Network-on-Chip (NoC) verwaltet wird, reduziert den Strom verbrauch durch das Senden von Daten in flexiblen Paketen. Dieser Ansatz senkt die physische Draht zahl und verbessert die Leistung.Andere Techniken verbessern diese Effizienz weiter:
- Feinkörniges Gating: Diese Methode verwendet Clock Gating, um den Datenfluss zwischen Hardware einheiten zu regulieren.
- Pufferung: Explizite Puffer (FIFOs) stellen sicher, dass Daten genau dann verfügbar sind, wenn der KI-Beschleuniger sie benötigt, und verhindern Ställe und Energie verschwendung.
DEDIZIERTE HARDWARE-BESCHLEUNIGUNG
Die NPU ist der Star-Spieler, aber nicht der einzige Hardware-Beschleuniger im Team. HiSilicon-SoCs integrieren eine Suite dedizierter Hardware beschleuniger, die bestimmte Aufgaben erledigen. Diese Beschleuniger entladen die Arbeit von der CPU und der NPU und reduzieren die End-to-End-Latenz der gesamten KI-Pipeline. Dieser Ansatz ist für komplexe Aufgaben wie die Echtzeit-Video analyze von entscheidender Bedeutung und ermöglicht eine effektive Inferenz auf dem Gerät.
In Computer Vision Anwendungen, dieBildsignal prozessor (ISP)Ist ein entscheidender Hardware-Beschleuniger. Der ISP arbeitet direkt mit der NPU zusammen, um eine bessere Inferenz leistung zu erzielen.
- Der ISP übernimmt erste Bild verarbeitung aufgaben wie HDR-Fusion (High Dynamic Range) und erweiterte Rausch unterdrückung.
- Es bereitet die Videodaten speziell für die auf der NPU laufenden KI-Modelle vor und optimiert sie.
- Diese Vor verarbeitung durch einen dedizierten Hardware beschleuniger bedeutet, dass die NPU saubere, bereit zu analysierende Daten erhält, was das endgültige KI-Ergebnis beschleunigt.
In ähnlicher Weise sind hardware basierte Video codierer und-decoder wesentliche KI-Beschleuniger für die Analyse hoch auflösender Videostreams. Diese Beschleuniger verwalten die gesamte Video verarbeitung pipeline auf einem einzigen Chip.
- Sie dekodieren eingehende Videostreams, ohne die CPU zu belasten.
- Sie ermöglichen es der NPU, das Video lokal zu analysieren.
- Sie übertragen nur kritische Ereignis daten, was die Netzwerk bandbreite und die Speicher kosten drastisch reduziert.
Dieses Team spezial isierter Hardware beschleuniger stellt sicher, dass jede Phase einer KI-Aufgabe, von der Daten erfassung bis zur endgültigen Ausgabe, auf Geschwindigkeit optimiert ist. Dieser umfassende Ansatz für das Hardware-Design verleiht HiSilicon einen Vorteil bei der Leistung mit geringer Latenz für Echtzeit-KI. Die Synergie zwischen diesen Beschleunigern liefert ein Leistungs niveau, das ein einzelner Prozessor nicht erreichen kann.
REAL-WORLD LOW-LATENCY-ANWENDUNGEN
Hardware mit niedriger Latenz entsperrt eine neue Generation intelligenter Systeme. Die Leistung dieser Systeme hängt von der sofortigen Datenverarbeitung ab. Die Hardware architektur von HiSilicon bietet die Geschwindigkeit, die für kritische KI-Anwendungen in der realen Welt erforderlich ist. Die überlegene Leistung seiner KI-Modelle ermöglicht eine sofortige Entscheidung sfindung, bei der Millisekunden wichtig sind.
AUTONOME SYSTEME
In autonomen Systemen ist eine geringe Latenz eine nicht verhandelbare Voraussetzung für Sicherheit und Präzision. Die Hardware muss verarbeitenSensorDaten und führen KI-Modelle mit minimaler Verzögerung aus, um eine zuverlässige Leistung sicher zustellen.
- Autonome Fahrzeuge: Für ein selbst fahrendes Auto erfordert das Erkennen eines Fußgängers und das Betätigen der Bremsen eineEnde-zu-Ende-Latenz von 50 bis 100 Millisekunden. Jede Verzögerung, die darüber hinaus geht, beeint rächt igt die Sicherheit. Die Hardware des Fahrzeugs muss diese Leistung konsequent liefern.
- Industrie robotik: Auf einemMontageLinie, Roboter brauchen schnelles Feedback, um präzise Aufgaben auszuführen.Sub-100ms Ausführungs zyklenFür KI-Modelle erlaubenBessere Qualitäts kontrolle und erhöhte Arbeits sicherheit. Diese Hardware leistung mit geringer Latenz verbessert direkt den Fertigungs durchsatz.
INTELLIGENTE INFRASTRUKTUR
Intelligente Städte und Fabriken verwenden KI-Analysen vor der Kamera, um Effizienz und Sicherheit zu verbessern. Dies erfordert leistungs starke Edge-Hardware, die in der Lage ist, Videostreams in Echtzeit zu verarbeiten. Die Leistung dieser KI-Modelle ist der Schlüssel zu ihrem Erfolg.
Echtzeit-Bedrohung erkennung:In Smart Cities überwachen KI-Kameras den öffentlichen Raum. Die Hardware analysiert Video-Feeds zuIdentifizieren Sie Verkehrs verstöße, verlassene Objekte oder andere potenzielle Bedrohungen, um eine sofortige Reaktion zu ermöglichen. Diese KI-Leistung hilft Straf verfolgung und optimiert Rettungs dienste.
In intelligenten Fabriken,KI-Vision-Systeme bieten sofortige Qualitäts kontrolle. Die Hardware führt Inspektions modelle aus, die Produkte am Fließband analysieren,Identifizieren von Defekten wie Kratzern oder Fehlstellungen. Dieses sofortige Feedback verbessert die Produkt qualität, ohne die Produktion zu verlangsamen. Die Leistung der KI-Modelle ist hier von entscheidender Bedeutung.
INTELLIGENTE GERÄTE UND MEDIEN
Die Verarbeitung von KI mit geringer Latenz verbessert die Benutzer erfahrung in Unterhaltung elektronik und Gesundheits geräten. Die Hardware ermöglicht anspruchs volle Funktionen, die direkt auf dem Gerät ausgeführt werden.
Smart-TVs verwendenKI-Modelle für Echtzeit-Upscaling von 8K-Videos. Der KI-Prozessor der Hardware analysiert den Inhalt Frame-by-Frame, um Details zu verbessern und Rauschen zu reduzierenUnd liefert ein überlegenes Bild. Diese Leistung auf hohem Niveau geschieht sofort. Für Telemedizin und Wearables,Hardware auf dem GerätAnalysiert biometrische Daten.Modelle zur Erkennung von Notfällen erfordern eine Latenz von weniger als 50 msUm Benutzer oder medizinisches Personal zu alarmieren. Diese schnelle KI-Leistung kann lebens rettend sein.
Für Echtzeit-Edge-KI ist die End-to-End-Latenz von Bedeutung.Roher Rechen durchsatz allein definiert keine echte Hardware leistung. Die Hardware architektur von HiSilicon mit seiner Da Vinci NPU und dedizierten Hardware beschleunigern bietet diese kritische Leistung mit niedriger Latenz. Die Leistung dieser Hardware-Beschleuniger ist der Schlüssel. Die Hardware-Beschleuniger bieten eine hervorragende Leistung.
Hinweis für Entwickler:Sie müssen Hardware für die Latenz als Benchmark bewerten. Dies garantiert echte Hardware leistung und Zuverlässigkeit. Latenz ist für diese Hardware leistung wichtig. Die Hardware beschleuniger und die Hardware liefern diese Leistung. Die Leistung der Hardware-Beschleuniger ist von entscheidender Bedeutung. Die Hardware leistung hängt von diesen Hardware beschleunigern ab.
FAQ
Warum ist Latenz für Edge AI wichtiger als TOPS?
TOPS misst die rohe Verarbeitung leistung. Die Latenz misst die Gesamtzeit für eine Entscheidung. Für Echtzeit anwendungen wie das autonome Fahren ist eine schnelle Entscheidung für Sicherheit und Leistung wichtiger als nur ein hoher Rechen durchsatz.
Eine geringe Latenz stellt sicher, dass das System sofort auf neue Informationen reagieren kann.
Was ist die Da Vinci NPU?
Die Da Vinci NPU ist der spezial isierte KI-Beschleuniger von HiSilicon. Es verwendet eine einzigartige 3D Cube-Architektur für Matrix-Mathe. Dieses Design beschleunigt die Berechnungen von KI-Modellen erheblich. Es reduziert direkt die Inferenz latenz und verbessert die Gesamtsystem leistung für Echtzeit aufgaben.
Wie verbessern Hardware beschleuniger die KI-Leistung?
Hardware beschleuniger wie ein Bildsignal prozessor (ISP) verarbeiten bestimmte Aufträge. Sie entladen Aufgaben vom Hauptprozessor. Diese parallele Verarbeitung reduziert Engpässe. Die gesamte KI-Pipeline läuft schneller, verringert die End-to-End-Latenz und ermöglicht eine effiziente Inferenz auf dem Gerät.
Welche Anwendungen erfordern eine extrem niedrige Latenz?
Anwendungen, die sofortige Maßnahmen benötigen, erfordern eine geringe Latenz. Diese Systeme hängen von einer schnellen Entscheidung sfindung in Echtzeit ab. Wichtige Beispiele sind:
- Autonome Systeme (Fahrzeuge, Robotik)🤖
- Intelligente Infrastruktur (Bedrohung erkennung)🏙️
- Fort geschrittene Medien (8K-Upscaling)📺
- Telemedizin (Notfall warnungen)❤️🩹





