

Processamento AI em tempo real Por que a latência é fundamental para o HiSilicon
Para os SoCs HiSilicon AI, a baixa latência é a métrica de desempenho mais crítica. Este foco hardware em baixa latência desempenho e

Para os SoCs HiSilicon AI, a baixa latência é a métrica de desempenho mais crítica. Esse foco do hardware no desempenho de baixa latência permite o processamento de dados em tempo real. O crescimento do mercado de IA para um projetadoUS $143 bilhões até 2034Destaca a demanda por esse desempenho do hardware. Em sistemas onde a latência importa,Um atraso superior a 100 milissegundos degrada o desempenho da segurança-A. A arquitetura de hardware especializada da HiSilicon prioriza esse desempenho de latência de ponta a ponta. Este projeto do hardware assegura o desempenho superior do AI do mundo real.TOPS RAW não reflete o verdadeiro desempenho do hardware-A. Esse foco no desempenho de latência é fundamental para o desempenho do hardware da IA, pois o próprio hardware é o núcleo do desempenho do hardware da IA.
Principais Takeaways
- A baixa latência é muito importante para os chips AI da HiSilicon. Significa que oChipToma decisões rapidamente, o que é fundamental para tarefas em tempo real.
- O design especial da HiSilicon, chamado NPU Da Vinci, ajuda os modelos de IA a funcionarem rapidamente. Ele usa um cubo 3D exclusivo para fazer matemática rapidamente.
- As peças especiais noChip, Como o Image Signal Processor, ajuda a parte principal do AI. Eles tornam todo o sistema mais rápido, fazendo trabalhos específicos.
- O processamento rápido de IA ajuda carros autônomos, cidades inteligentes e dispositivos inteligentes. Isso os torna mais seguros e funcionam melhor na vida real.
PORQUE A LATÊNCIA IMPORTA NA EDGE AI

Em aplicativos Edge AI, cada milissegundo conta. O sistema deve processar fluxos de dados em tempo real, onde ficar para trás pode levar a eventos perdidos ou ações incorretas. É por isso que a latência importa. Algoritmos de controle dependem de inferência imediata para manter a estabilidade e segurança. Um atraso pode comprometer todo o desempenho do sistema.O verdadeiro desempenho do hardware não é apenas sobre o poder de processamento; é sobre a velocidade da saída final e acionável.
DEFINIÇÕES DE LATÊNCIA DE PROCESSAMENTO AI
Profissionais definem formalmente a latência de inferência como o tempo que um modelo de IA leva para receber uma entrada e retornar uma previsão. Esta medida é tipicamente expressa em milissegundos (ms).No entanto, a latência de ponta a ponta fornece uma imagem mais completa do desempenho do sistema. Abrange toda a jornada desde a captura de dados até a ação final.
Essa latência total inclui vários estágios distintos:
- Ingestão e Pré-processamento Dados: O hardware primeiro prepara os dados. Esta etapa envolve formatar e validar os dados antes que eles atinjam os modelos AI.
- Inferência modelo: Este é o tempo do núcleo computacional. O hardware executa os modelos AI para gerar uma previsão com base nos dados de entrada. O desempenho inferência aqui é crítico.
- Pós-processamento e saída: O hardware formata a saída do modelo. Ele prepara o resultado para o próximo componente do sistema, como um controlador de braço robótico ou um monitor.
Nota:Para IA interativa, outras métricas também destacam o desempenho do hardware.Tempo para o primeiro token (TTFT)Mede a rapidez com que um usuário recebe a primeira parte de uma resposta, o que é vital para uma experiência de usuário suave.
LIMITAÇÕES DO CPUS DE FINALIDADE GERAL
As CPUs de uso geral não são construídas para as demandas da IA moderna.CPUs usam um pequeno número de núcleos poderosos, geralmente entre 4 e 64. Essa arquitetura se destaca em tarefas complexas e sequenciais. No entanto, os modelos de IA exigem cálculos massivamente paralelos, executando milhares de operações simples de uma só vez. Essa incompatibilidade cria gargalo significativo no desempenho.O design da CPU limita seu desempenho de inferência para cargas paralelas.
Mesmo em sistemas com uma GPU poderosa, a CPU pode restringir o desempenho geral, especialmente em aplicativos sensíveis à latência.A CPU se esforça para alimentar os dados para o acelerador com rapidez suficiente, o que prejudica o desempenho de inferência do sistema. É por isso queHardware especializadoÉ necessário para o desempenho ideal AI.
Benchmarks mostram claramente a diferença de desempenho entre CPUs e hardware especializadoUnidades Processamento Neural(UCN). Para modelos AI comuns como o YOLOV3, as NPUs oferecem desempenho de inferência muito melhor.
| Tipo do sistema | Redução Latência Relativa |
|---|---|
| Sistema Apenas CPU | Bases |
| Sistema alimentado por NPU | ~ 1.6x Mais Rápido |
Esses dados mostram que o hardware dedicado reduz significativamente o tempo necessário para executar modelos de IA. A vantagem arquitetônica das NPUs se traduz diretamente em menor latência e desempenho superior de inferência. O gráfico abaixo ilustra ainda como diferentes plataformas de hardware especializadas alcançam latência variável para modelos de IA populares.
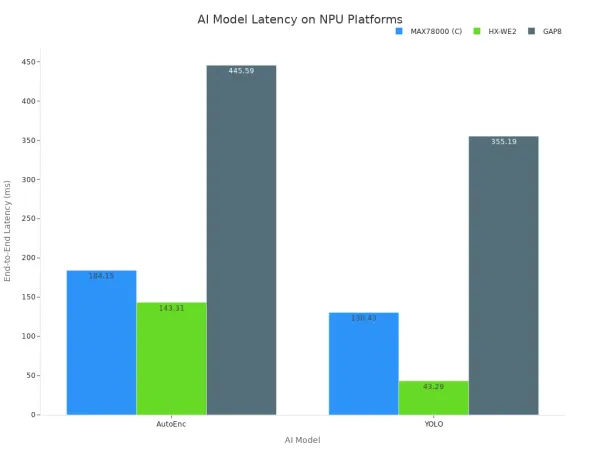
Em última análise, confiar em CPUs para tarefas de IA em tempo real compromete a responsividade do sistema. O hardware simplesmente não é projetado para o trabalho. Alcançar a baixa latência que importa requer hardware desenvolvido especificamente para modelos de IA, garantindo desempenho e confiabilidade de inferência de alto nível.
ARQUITECTURA DE HISILICONN PARA BAIXA LATÊNCIA

A HiSilicon alcança seu desempenho de baixa latência líder do setor por meio de uma arquitetura holística. Esse design vai além de um único processador poderoso. Ele integra núcleos computacionais especializados, uma alta velocidadeMemóriaSistema e aceleradores de hardware dedicados. Essa combinação garante que os dados sejam movimentados e processados com a máxima eficiência, o que é essencial para aplicativos de IA em tempo real. O desempenho geral do sistema depende dessa integração estreita.
O NPU DA VINCI CORE
A Unidade de Processamento Neural Da Vinci (NPU) é o coração do hardware AI da HiSilicon. Este NPU é um poderoso acelerador AI projetado especificamente para as operações matemáticas que alimentamModelos modernos AI-A. Sua arquitetura não é uniforme; ele combina diferentes tipos de unidades de computação para otimizar o desempenho. EsteDesign heterogêneoÉ uma razão chave para o seu excelente desempenho inferência.
O núcleo contém três componentes principais trabalhando juntos:
- Unidades escalares: Lógica geral e fluxo de controle para modelos de IA.
- Unidades vetoriaisEstes são excelentes para executar muitas operações simples ao mesmo tempo, uma necessidade comum para certas camadas em modelos de IA.
- Unidades Cubo 3D: Este é o componente mais crítico para a aceleração AI. Essas unidades são construídas para realizar multiplicação matricial em velocidades incríveis.
Essa estrutura permite que o núcleo Da Vinci processe modelos complexos de IA com atraso mínimo. As unidades cúbicas lidam com o trabalho pesado da matemática matricial, enquanto as unidades vetoriais e escalares gerenciam as tarefas circundantes. Essa divisão de trabalho dentro do acelerador de IA garante que nenhuma parte do hardware crie um gargalo. O resultado é desempenho superior e menor latência para cargas de trabalho exigentes. Esses aceleradores de IA são fundamentais para o desempenho geral do sistema.
MEMÓRIA E INTERLIGAÇÕES ON-CHIP
Um NPU rápido requer dados rápidos. Se o acelerador AI deve aguardar dados, sua vantagem de desempenho é perdida. O design de hardware da HiSilicon aborda esse desafio com uma sofisticada hierarquia de memória no chip e interconexões de alta velocidade. Esses componentes criam uma superestrada de dados, minimizando a latência associada à movimentação de informações pelo chip. Esse fluxo de dados eficiente é crítico para o desempenho do hardware.
Os SoCs HiSilicon usam interconexões avançadas para vincular a NPU, a CPU e a memória. Isso garante que todos os componentes possam se comunicar com atraso mínimo. A escolha da tecnologia de memória também desempenha um papel vital no desempenho do sistema.
| Modelo Chip | Interconexão | Tecnologia Memória |
|---|---|---|
| Kirin 960 | BRAÇO | LPDDR4-1600 (canal duplo de 64 bits) |
| Kirin 970 | BRAÇO | LPDDR4 |
Além da memória principal, o sistema usa várias camadas de memória no chip (caches). A própria NPU Da Vinci contém sua própria memória local. Isso permite que o acelerador de IA mantenha os dados usados com frequência para modelos de IA ao lado das unidades computacionais, reduzindo drasticamente a latência do acesso aos dados. Essa arquitetura também melhora a eficiência energética.O fluxo de dados eficiente no chip, geralmente gerenciado por um Network-on-Chip (NoC), reduz o consumo de energia enviando dados em pacotes flexíveis. Esta aproximação abaixa a contagem física do fio e melhora o desempenho.Outras técnicas aumentam ainda mais essa eficiência:
- Gating de grão fino: Este método usa clock gating para regular o fluxo de dados entre hardware.
- TampãoOs buffers explícitos (FIFOs) garantem que os dados estejam disponíveis precisamente quando o acelerador de IA precisar, evitando estacas e desperdício de energia.
ACELERAÇÃO DE HARDWARE DEDICADA
O NPU é o jogador estrela, mas não é o único acelerador de hardware da equipe. O HiSilicon SoCs integra um conjunto de aceleradores de hardware dedicados que lidam com tarefas específicas. Esses aceleradores descarregam o trabalho da CPU e da NPU, reduzindo a latência de ponta a ponta de todo o pipeline de IA. Essa abordagem é vital para tarefas complexas, como análise de vídeo em tempo real e permite inferência eficaz no dispositivo.
Em aplicações de visão computacional,Processador De Sinal De Imagem (ISP)Acelerador de hardware crucial. O ISP trabalha diretamente com o NPU para oferecer melhor desempenho inferência.
- O ISP lida com tarefas iniciais de processamento de imagem como HDR (High Dynamic Range) e redução de ruído.
- Ele prepara e otimiza os dados de vídeo especificamente para os modelos de IA executados no NPU.
- Esse pré-processamento por um acelerador de hardware dedicado significa que a NPU recebe dados limpos e prontos para análise, o que acelera o resultado final da IA.
Da mesma forma, codificadores e decodificadores de vídeo baseados em hardware são aceleradores essenciais para analisar fluxos de vídeo de alta resolução. Esses aceleradores gerenciam todo o pipeline de processamento de vídeo em um único chip.
- Eles decodificam os fluxos de vídeo sem sobrecarregar a CPU.
- Eles permitem que a NPU analise o vídeo localmente.
- Eles transmitem apenas dados críticos, o que reduz drasticamente a largura de banda e os custos de armazenamento.
Essa equipe de aceleradores de hardware especializados garante que todas as etapas de uma tarefa de IA, desde a captura de dados até a saída final, sejam otimizadas para velocidade. Essa abordagem abrangente ao design de hardware é o que dá à HiSilicon sua vantagem no desempenho de baixa latência para IA em tempo real. A sinergia entre esses aceleradores oferece um nível de desempenho que um único processador não pode igualar.
APLICAÇÕES DE BAIXA LATÊNCIA DO MUNDO REAL
Hardware de baixa latência desbloqueia uma nova geração de sistemas inteligentes. O desempenho desses sistemas depende do processamento imediato de dados. A arquitetura de hardware da HiSilicon fornece a velocidade necessária para aplicativos críticos de IA do mundo real. O desempenho superior de seus modelos de IA permite tomar decisões instantâneas onde milissegundos importam.
SISTEMAS AUTÓNOMOS
Em sistemas autônomos, baixa latência é um requisito inegociável para segurança e precisão. O hardware deve processarSensorDados e executar modelos AI com atraso mínimo para garantir desempenho confiável.
- Veículos Autônomos: Para um carro autônomo, detectar um pedestre e aplicar os freios requer umLatência de ponta a ponta de 50 a 100 milissegundos-A. Qualquer atraso além disso compromete a segurança. O hardware do veículo deve fornecer esse desempenho consistentemente.
- Robótica Industrial: Em umMontagemOs robôs precisam de feedback rápido para executar tarefas precisas.Ciclos de execuçãoPara modelos de IA permitemMelhor qualidade controle e maior segurança do trabalhador. Esse desempenho de hardware de baixa latência melhora diretamente a produção-A.
INFRA-ESTRUTURA INTELIGENTE
Cidades e fábricas inteligentes usam análise de IA na câmera para melhorar a eficiência e a segurança. Isso requer hardware poderoso capaz de processar fluxos de vídeo em tempo real. O desempenho desses modelos de IA é fundamental para seu sucesso.
Detecção de ameaças em tempo real:Nas cidades inteligentes, as câmeras AI monitoram espaços públicos. O hardware analisa feeds de vídeoIdentificar violações de trânsito, objetos abandonados ou outras ameaças potenciais, permitindo uma resposta imediata. Este desempenho AI ajuda a aplicação da lei e otimiza serviços emergenciais-A.
Em fábricas inteligentes,Sistemas AI oferecem controle instantâneo de qualidade. O hardware executa os modelos da inspeção que analisam produtos na linha de montagemPor exemplo,Identificar defeitos como arranhões ou desalinhamentos-A. Este feedback imediato melhora a qualidade do produto sem retardar a produção. O desempenho dos modelos AI é crítico aqui.
DISPOSITIVOS INTELIGENTES E MÍDIA
O processamento de IA de baixa latência melhora a experiência do usuário em eletrônicos e dispositivos de saúde. O hardware permite recursos sofisticados que são executados diretamente no dispositivo.
As Smart TVs usamModelos AI para upscaling de vídeo 8K em tempo real. O processador AI do hardware analisa o conteúdo quadro a quadro para melhorar os detalhes e reduzir o ruído, Entregando uma imagem superior. Esse desempenho de alto nível acontece instantaneamente. Para telemedicina e wearables,Hardware no dispositivoAnalisa dados biométricos.A detecção de eventos de emergência requer latência inferior a 50 msPara alertar usuários ou pessoal médico. Esse rápido desempenho de IA pode salvar vidas.
Para IA de borda em tempo real, a latência de ponta a ponta é importante.O rendimento computacional bruto sozinho não define o desempenho verdadeiro do hardware-A. A arquitetura de hardware da HiSilicon, com sua NPU Da Vinci e aceleradores de hardware dedicados, oferece esse desempenho crítico de baixa latência. O desempenho desses aceleradores de hardware é fundamental. Os aceleradores do hardware fornecem o desempenho excelente.
Nota para os desenvolvedores:Você deve comparar hardware para latência. Isso garante desempenho e confiabilidade do hardware do mundo real. A latência importa para o desempenho deste hardware. Os aceleradores do hardware e o hardware entregam este desempenho. O desempenho dos aceleradores do hardware é vital. O desempenho do hardware depende desses aceleradores de hardware.
FAQ
Por que a latência é mais importante do que o TOPS para Edge AI?
O TOPS mede o poder bruto do processamento. A latência mede o tempo total de uma decisão. Para aplicações em tempo real, como a condução autônoma, uma decisão rápida é mais crítica para a segurança e o desempenho do que apenas o alto rendimento computacional.
Uma baixa latência garante que o sistema possa reagir instantaneamente a novas informações.
O que é a NPU Da Vinci?
O NPU Da Vinci é o acelerador AI especializado da HiSilicon. Ele usa uma arquitetura 3D Cube única para matemática matricial. Este projeto acelera significativamente os cálculos do modelo AI. Ele reduz diretamente a latência de inferência e melhora o desempenho geral do sistema para tarefas em tempo real.
Como os aceleradores de hardware melhoram o desempenho?
Aceleradores de hardware, como o Image Signal Processor (ISP), lidam com tarefas específicas. Eles descarregam tarefas do processador principal. Esse processamento paralelo reduz os gargalos. Todo o pipeline de IA é executado mais rápido, reduzindo a latência de ponta a ponta e permitindo uma inferência eficiente no dispositivo.
Quais aplicativos exigem latência ultra baixa?
Aplicações que requerem ação imediata requerem baixa latência. Esses sistemas dependem de tomadas de decisão rápidas e em tempo real. Exemplos chave incluem:
- Sistemas autônomos (veículos, robótica)🤖
- Infraestrutura inteligente (detecção de ameaças)🏙️
- Mídia avançada (upscaling 8K)📺
- Telemedicina (alertas emergenciais)❤️🩹




