

Inference Throughput Battle HiSilicon Takes on Generic SoCs
HiSilicon SoCs deliver superior performance in computer vision. Their dedicated NPU provides excellent throughput and power

HiSilicon SoCs deliver superior performance in computer vision. Their dedicated NPU provides excellent throughput and power efficiency. This specialized hardware design results in lower power consumption and higher efficiency during inference. This performance makes the HiSilicon SoC a leader in benchmarking computer vision inference.
On the other hand, a generic SoC offers a different advantage. This type of SoC provides superior software flexibility. Its broad open-source support is a key feature.
This flexibility is critical for diverse workloads. The general performance of a generic SoC supports rapid development. The specific NPU in a HiSilicon SoC, however, maximizes throughput and power efficiency for computer vision inference.
Key Takeaways
- HiSilicon SoCs have a special part called an NPU. This NPU helps them process computer vision tasks very fast and use less power.
- Generic SoCs are more flexible. They work well for many different tasks because they have good software support.
- Benchmarking helps us compare SoCs. We look at how many images they process per second, how fast they work, and how much power they use.
- HiSilicon SoCs use less power for the work they do. This is important for devices that run on batteries.
- The total cost of an SoC includes its price and how much work it takes to set up. HiSilicon SoCs can save money in the long run due to their efficiency.
BENCHMARKING COMPUTER VISION INFERENCE

Benchmarking computer vision inference requires a specialized approach. It moves beyond simple speed tests to evaluate a system's holistic capabilities. A proper benchmark provides a clear picture of an SoC's real-world performance and efficiency. This process is essential for comparing a dedicated HiSilicon SoC against a generic SoC.
KEY PERFORMANCE METRICS
Effective benchmarking relies on a core set of performance metrics. These metrics measure how well a system handles computer vision tasks. They provide the data needed for a direct comparison.
- Throughput (FPS): Frames Per Second measures how many images the SoC can process in one second. Higher throughput indicates better performance for video streams.
- Inference Time: This is the latency, or time taken, for a single inference. Lower inference time is critical for real-time applications.
- Power Consumption: Measured in watts, this shows the power an SoC draws during continuous inference. Lower power usage is vital for battery-operated devices.
A crucial combined metric is performance-per-watt (FPS/Watt). This metric connects throughput directly to power consumption. It reveals the true energy efficiency of an SoC, which is a key factor for edge devices where both performance and power are constrained.
ACCURACY AND VARIABILITY
AI benchmarking differs significantly from traditional benchmarking. Speed alone is not enough. A model's accuracy is equally important. A fast inference is useless if the results are wrong. For computer vision, evaluators use metrics like mean Average Precision (mAP) to measure a model's prediction accuracy. This ensures a balance between performance and correctness.
Performance can also vary. The same AI model often shows different performance on different hardware. This variability comes from several factors:
| Factor | Description |
|---|---|
| Inference Engines | Specialized software like TensorRT optimizes models for specific hardware, causing performance differences between each SoC. |
| Quantization | Techniques like INT8 reduce model size, which can boost inference speed and lower power usage but may slightly impact accuracy. |
| Software Versions | Different versions of frameworks like PyTorch or TensorFlow can affect an SoC's final performance and efficiency. |
Standardized tests like the MLPerf Mobile benchmark help control these variables. The MLPerf Mobile benchmark provides a framework for fair benchmarking. The MLPerf Mobile benchmark is a key tool for mobile AI benchmarking. Analysts use the MLPerf Mobile benchmark to compare mobile SoCs. The MLPerf Mobile benchmark evaluates both inference performance and accuracy. The MLPerf Mobile benchmark is the industry standard. The MLPerf Mobile benchmark ensures results are comparable. The MLPerf Mobile benchmark is essential for this analysis. The MLPerf Mobile benchmark helps quantify the efficiency of computer vision inference. The MLPerf Mobile benchmark provides reliable data.
THROUGHPUT AND LATENCY
Throughput and latency are the most critical metrics for evaluating real-world inference performance. High throughput means an SoC can process more data, while low latency ensures rapid responses. A benchmark analysis reveals a clear architectural divide. HiSilicon SoCs use specialized hardware to maximize performance. Generic SoCs rely on flexible but less optimized processing units. This difference directly impacts their computer vision capabilities.
HISILICON'S NPU ADVANTAGE
HiSilicon SoCs achieve superior throughput and low latency through their dedicated Neural Processing Unit (NPU). This NPU is not a general-purpose processor. It is specialized hardware engineered specifically for AI workloads. This design gives the HiSilicon SoC a significant performance advantage in computer vision inference.
The DaVinci architecture is the core of this advantage. It includes several key features that accelerate AI operations:
- 3D Cube Engine: This engine excels at matrix multiplication, a fundamental operation in neural networks. It can execute thousands of operations per clock cycle, dramatically speeding up inference.
- Vector Unit: This component handles specialized functions and various data types, which increases the NPU's versatility and efficiency.
- Multi-Core Design: Top-tier HiSilicon SoCs integrate multiple NPU cores. These cores work in parallel to boost overall throughput for demanding tasks.
Data movement often creates performance bottlenecks. The HiSilicon NPU minimizes this issue with a sophisticated memory system. It features extremely high-bandwidth memory and a multi-level cache optimized for AI. This architecture ensures the NPU cores receive data quickly, reducing idle time and lowering latency. The result is exceptional efficiency and performance for real-time inference.
GENERIC SOC PERFORMANCE
A generic SoC handles AI workloads differently. It typically uses its powerful Graphics Processing Unit (GPU) or an enhanced CPU instead of a fully dedicated NPU. While modern GPUs like the Qualcomm Adreno and ARM Mali are highly capable, their architecture is designed for a broader range of tasks. This lack of specialization leads to lower efficiency for AI inference compared to a dedicated NPU. Developers also face challenges optimizing models for varied GPU architectures, which can affect final performance.
Benchmark data for generic SoCs illustrates their performance characteristics. For example, tests on the YOLOv5 model show a wide range of latency figures across different Qualcomm Snapdragon SoCs.
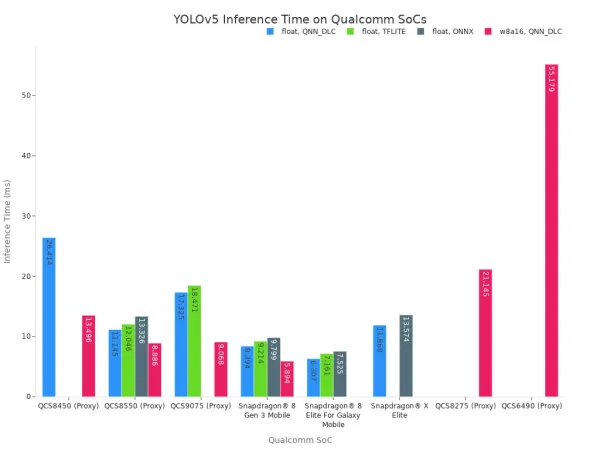
The following table highlights the latency for a few powerful generic SoCs. Lower latency is better, as it enables faster inference.
| SoC Model | Quantization | Backend | Inference Time (ms) |
|---|---|---|---|
| Snapdragon® 8 Gen 3 | float | QNN_DLC | 8.394 |
| Snapdragon® 8 Gen 3 | w8a16 | QNN_DLC | 5.894 |
| Snapdragon® X Elite | float | QNN_DLC | 11.868 |
This benchmark shows that a high-end generic SoC delivers strong performance. Techniques like quantization (w8a16) further reduce latency and power consumption. However, the reliance on a GPU or a less specialized NPU means the SoC expends more power and resources than a HiSilicon SoC with its purpose-built NPU. The generic SoC must balance AI tasks with other system processes, limiting its peak throughput and efficiency for sustained computer vision workloads. This trade-off between flexibility and raw power defines the performance of a generic SoC.
POWER EFFICIENCY ANALYSIS
Beyond raw speed, power efficiency is a critical battleground for modern processors. An SoC can deliver high throughput, but its value diminishes if it consumes excessive power. This is especially true for edge devices that often rely on batteries or have strict thermal limits. The performance-per-watt metric, therefore, becomes the ultimate measure of an SoC's design excellence. An analysis of this metric reveals the significant architectural advantages of a specialized NPU. The overall performance of any SoC depends heavily on its power efficiency.
HISILICON'S FPS/WATT LEAD
HiSilicon SoCs consistently demonstrate a lead in performance-per-watt. This superior efficiency is not an accident; it is a direct result of the purpose-built NPU. The NPU architecture executes neural network operations using specialized circuits that consume far less power than general-purpose processors. This design allows the SoC to achieve high inference throughput while maintaining a low power draw.
The concept of performance-per-watt (FPS/Watt) is central to evaluating true efficiency. It quantifies how much performance an SoC delivers for every watt of power it consumes. A higher value indicates better power efficiency, which is essential for creating sustainable and cost-effective AI solutions.
Industry-standard evaluations like the MLPerf benchmark use a strict methodology to ensure fair and accurate power measurements. This benchmark process provides a reliable basis for comparing the efficiency of different hardware. Key aspects of this methodology include:
- Precise Alignment: Power measurements are synchronized exactly with the AI inference workload.
- Sustained Testing: The benchmark runs for at least 60 seconds to capture power consumption under a continuous load, reflecting real-world conditions.
- Unified Metrics: The benchmark calculates efficiency as Samples per Joule, providing a standardized way to assess performance-per-watt.
This rigorous benchmark approach validates the efficiency of the HiSilicon NPU. The specialized design minimizes wasted energy, giving HiSilicon SoCs a decisive edge in power-sensitive applications. The NPU handles the AI workload, allowing other parts of the SoC to remain in low-power states, further boosting overall efficiency.
GENERIC SOC POWER DRAW
Generic SoCs take a different approach that results in a higher power draw for AI tasks. Instead of a highly specialized NPU, they typically offload inference workloads to their integrated GPU or enhanced CPU cores. While powerful, these components are not optimized solely for neural network mathematics. This lack of specialization leads to lower power efficiency. The power draw of an edge device can range from a few milliwatts for simple sensors to tens of watts for complex edge servers. A generic SoC in a smart camera often falls in the middle, creating a challenging balance between performance and power consumption.
For example, a generic SoC like the Rockchip RK3588, which contains a capable NPU, still exhibits a significant power draw under load. Benchmark tests on an industrial motherboard with this SoC show a power draw between 8–12 watts during a sustained AI vision workload.
| Model | Power Draw (W) | Efficiency (FPS/W) |
|---|---|---|
| RK3588 Industrial Motherboard | 8–12 | 4.2–6.2 |
This data shows a respectable FPS per watt figure, but the overall power draw is considerable for an embedded device. The reliance on a less-specialized NPU or a GPU means the SoC expends more energy to achieve its performance targets. Offloading an inference task from a CPU to a GPU can improve speed, but it often increases total power draw. This higher power draw creates another major problem: heat.
Sustained high power draw generates significant thermal output. When an SoC gets too hot, it engages thermal throttling, a self-preservation mechanism that automatically reduces the processor's clock speed. This lowers performance to prevent heat damage. Heavy computer vision tasks can trigger thermal throttling on a generic SoC within seconds, degrading throughput and making performance inconsistent. This forces designers to add active cooling solutions like fans, which increases the device's size, cost, and total power draw. The fundamental trade-off for a generic SoC is clear: its flexibility comes at the cost of higher power consumption and the associated thermal challenges.
TOTAL COST OF OWNERSHIP

A complete cost-performance analysis extends beyond a simple benchmark. It must account for the total cost of ownership, which includes both initial hardware expenses and long-term development efforts. The final cost of a product depends heavily on these factors. A low-cost SoC can become expensive if it requires extensive engineering. This evaluation provides a realistic view of the true investment needed for each platform.
UPFRONT HARDWARE COSTS
The initial hardware cost is the most visible expense. A HiSilicon SoC often presents an attractive price point for its high performance. However, the cost of the development board is a more practical starting point for comparison. Development kits provide the necessary environment for prototyping and testing. The price of these kits can vary significantly.
| SoC Type | Board Name | SoC Model | Retail Cost |
|---|---|---|---|
| HiSilicon | HiKey | Kirin 620 | $129 |
| Generic ARM | Juno Versatile Express | Octacore Juno SoC | Pricey |
This comparison shows that a specialized SoC can offer a lower entry cost for hardware. This initial saving is an important factor. It allows teams to begin development without a large upfront investment. The lower hardware cost contributes positively to the overall cost-performance metric.
DEVELOPMENT AND INTEGRATION
Development and integration represent a significant, often hidden, cost. This is where Non-Recurring Engineering (NRE) expenses appear. NRE is the one-time cost to design, test, and prepare a new product for manufacturing. A complex SoC requires a substantial NRE budget.
Key NRE tasks include:
- Initial product design and engineering
- Software and firmware development
- Prototype creation and testing
- Regulatory certifications (e.g., FCC, CE)
The NRE cost for a modern SoC design can easily reach $1 million. This high cost reflects the complexity of optimizing software for a specific hardware architecture to achieve target performance and power goals. A generic SoC with broad open-source support may lower this NRE cost. A specialized SoC might require more focused engineering effort, impacting the final cost. A thorough benchmark helps justify this investment by proving the system's power and efficiency.
For performance-critical applications, HiSilicon SoCs are the clear winner in benchmarking computer vision inference. The NPU's specialized hardware delivers superior throughput and power efficiency. This NPU design boosts inference performance and overall efficiency. The NPU's high throughput and low power consumption justify the development cost. The NPU's efficiency lowers the total cost of power.
Decision Guide:
- HiSilicon SoC: Choose this SoC for maximum computer vision inference throughput and efficiency. The NPU's excellent performance lowers power cost. The NPU's performance and efficiency reduce operational cost.
- Generic SoC: Choose this SoC when software flexibility reduces development cost for computer vision tasks. This SoC balances performance and cost.
FAQ
What is the main advantage of a HiSilicon SoC?
HiSilicon SoCs contain a dedicated Neural Processing Unit (NPU). This specialized hardware delivers superior throughput and power efficiency for computer vision tasks. The design achieves high performance while consuming minimal power.
Why would someone choose a generic SoC instead?
A generic SoC provides excellent software flexibility. Its broad open-source support accelerates development for diverse projects. This makes it a strong choice for applications that are not exclusively focused on AI inference.
What does FPS/Watt mean for an edge device?
FPS/Watt measures an SoC's energy efficiency. It shows how many frames the processor can handle for each watt of power it uses. A higher value indicates better efficiency, which is critical for battery-powered devices. 🔋
Does a generic SoC's GPU work for AI?
Yes, a generic SoC's GPU can run AI models effectively. However, a GPU is a general-purpose unit. It typically consumes more power and offers lower efficiency for sustained AI workloads compared to a specialized NPU.





