

Rendimiento de inferencia de visión de benchmarking en SoCs modernos
Benchmarking de inferencia de visión por computadora presenta una opción crítica para los desarrolladores de AI de borde: cómo seleccionar el hardware adecuado para

La inferencia de la visión por computadora presenta una opción crítica para los desarrolladores de inteligencia artificial de borde: cómo seleccionar el hardware adecuado para las aplicaciones críticas de rendimiento. HiSilicon SoCs, con sus unidades de procesamiento neuronal (NPUs) especializadas, ofrecen una respuesta clara. Proporcionarán un rendimiento y una eficiencia energética superiores en comparación con los SoC genéricos, a menudo a un precio competitivo.
Los desarrolladores citan constantemente el hardware como un desafío principal:
- El 44% lucha con el costo del rendimiento del procesamiento.
- 35% caraMemoriaLimitaciones de la huella.
- El 34% está preocupado por el alto consumo de energía.
Puntos clave
- Los SoCs HiSilicon especializados con NPUs son los mejores para tareas de visión. Procesan modelos de IA más rápido queChips generales.
- Los SoC de HiSilicon usan menos energía. Esto significa que los dispositivos pueden funcionar más tiempo con baterías y mantenerse más frescos.
- HiSilicon SoCs ofrecen un mejor valor. Ellos dan más rendimiento por cada dólar gastado.
- Los SoC de propósito general son buenos para muchas tareas. No siempre son los mejores para exigirAplicaciones de visión.
ARQUITECTURAS SOC COMPARADAS

Los sistemas en chips modernos (SoC) siguen dos rutas principales para manejar las cargas de trabajo de IA. Un camino utiliza hardware especializado para la máxima eficiencia. El otro utiliza procesadores de propósito general para una mayor flexibilidad. Comprender estas diferencias es clave para seleccionar el hardware adecuado.
LA VENTAJA NPU ESPECIALIZADA
SoCs especializados, como elHiSilicon Hi3519A y Hi3559A, Integran una Unidad de Procesamiento Neural (NPU) dedicada. Una NPU es un acelerador de IA construido específicamente para cálculos de redes neuronales. Este diseño proporciona una ventaja significativa de rendimiento y eficiencia para las tareas de visión.
Las NPU de HiSilicon contienen hardware específico que acelera las operaciones de IA.
- AMotor del cubo 3DManeja miles de cálculos matriciales por ciclo de reloj.
- Una ampliaUnidad vectorialAdmite múltiples tipos de datos y funciones clave.
Esta arquitectura permite a la NPUProcesar modelos de IA muy rápidamente mientras usa menos energía que un procesador de propósito general. El hardware está optimizado para un trabajo: ejecutar modelos de IA de manera eficiente.
💡NPU vs. GPU de un vistazo Si bien ambos pueden ejecutar modelos de IA, sus diseños principales son fundamentalmente diferentes. Una NPU es un especialista, mientras que una GPU es un generalista poderoso.
| Característica | NPU (Unidad de Procesamiento Neural) | GPU (Unidad de Procesamiento de Gráficos) |
|---|---|---|
| Propósito principal | Optimizado para tareas AI/ML, cálculos de redes neuronales | Procesamiento paralelo de propósito general, renderizado de gráficos |
| Enfoque de optimización | Minimizar la latencia, maximizar la eficiencia para la inferencia de AI | Procesamiento concurrente para tareas a gran escala |
| Memoria | Memoria en chip para reducir los retrasos de transferencia de datos | Memoria de alto ancho de banda para grandes conjuntos de datos |
| Casos de uso típicos | Inferencia en tiempo real en dispositivos de borde (teléfonos inteligentes, IoT) | Entrenamiento de modelos AI a gran escala, computación de alto rendimiento |
EL VERSÁTIL ENFOQUE CPU/GPU
SoCs de propósito general de marcas comoRockchip, Amlogic y NXPOfrecer una solución más versátil. Estos chips usan sus potentes CPU y GPU para ejecutar modelos de IA junto con otras tareas del sistema. Si bien es flexible, este enfoque a menudo comercia el rendimiento de inferencia en bruto por la versatilidad.
Incluso cuando estos SoC incluyen una NPU, el rendimiento puede ser un cuello de botella. Por ejemplo,El NXP i.MX 8M Plus puede luchar para lograr altas velocidades de fotogramas con modelos más nuevos como YOLOv8. Del mismo modo, el rendimiento en el popular Rockchip RK3588 varía ampliamente dependiendo de la complejidad del modelo, como se muestra a continuación.
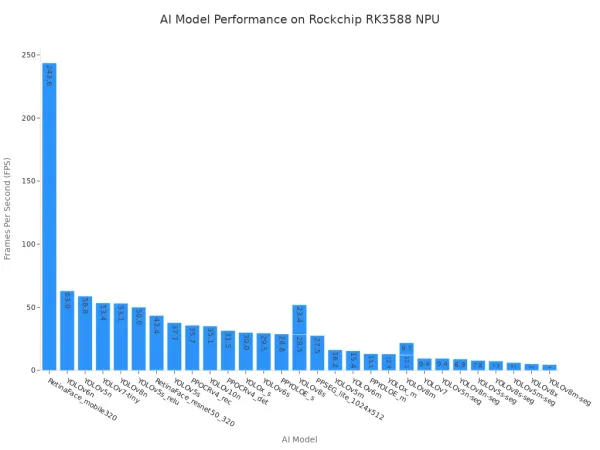
Esta variabilidad pone de relieve una compensación clave. Si bien estos SoC son excelentes para dispositivos multiuso, es posible que no brinden el rendimiento consistente y de alto rendimiento requerido para las aplicaciones dedicadas de visión por computadora.
BENCHMARKING METODOLOGÍA DE INFERENCIA DE LA VISIÓN COMPUTADORA

Una comparación fiable requiere una metodología transparente y coherente. Esta sección detalla el hardware, el software y las métricas utilizadas para la evaluación comparativa de la inferencia de visión por computadora. Este proceso garantiza una evaluación justa de las capacidades de cada SoC.
HARDWARE Y SELECCIÓN DE MODELOS
El punto de referencia incluye unSoC HiSiliconY varios SoCs de propósito general. Los chips genéricos proporcionan una línea de base para la comparación. La siguiente tabla muestra las especificaciones clave para los popularesRockchip SoCs, Que representa el enfoque versátil de CPU/GPU.
| SoC | Núcleos de CPU | Tipo de GPU | NPU TOPS |
|---|---|---|---|
| RK3566 | Cortex-A55 quad-core del brazo @ 1,8 GHz | Mali-G52 de brazo 2EE | 1 |
| RK3588 | 4 × Cortex-A76 y 4 × Cortex-A55 núcleos | ARM Mali-G610 MP4 | 6 |
Se seleccionaron dos modelos estándar de la industria para la prueba: YOLOv5 y ResNet-50. Estos modelos representan tareas comunes de detección de objetos y clasificación de imágenes. El modelo ResNet-50 tiene23,5 millones de parámetros y una complejidad computacional de 67,5 GFLOPs. La complejidad de las diferentes variantes de YOLOv5 se detalla a continuación.
| Modelo | Parámetros | GFLOPs |
|---|---|---|
| Hoteles en Yolov5m | 11,7 M | 30,9 |
| YOLOv5-ResNet-50 | 23,5 M | 67,5 |
| YOLOv5-ResNet-101 | 42,5 M | 128,4 |
| YOLOv5-EfficientNet-B0 | 4,0 M | 7,3 |
CONFIGURACIÓN DE SOFTWARE Y MARCO
El entorno de software afecta significativamente el rendimiento. Utilizamos marcos de inferencia livianos como TNN y NCNN, que están optimizados para dispositivos de borde. Para medir todo el potencial del hardware, los modelos se cuantificaron y probaron utilizando múltiples tipos de datos.
💡Materia de tipos de datos
- FP16 (Mitad de precisión):Ofrece un equilibrio entre precisión y rendimiento.
- INT8 (entero de 8 bits):Proporciona las velocidades de inferencia más rápidas y el menor consumo de energía, ideal para NPU.
Esta configuración permite una comparación directa de cómo cada SoC maneja optimizado, listo para producciónModelos AI.
MÉTRICAS CLAVE DE RENDIMIENTO
El núcleo de la inferencia de la visión por computadora se basa en tres métricas clave. Estas métricas proporcionan una imagen completa del rendimiento, la eficiencia y el valor.
- Rendimiento (FPS):Mide cuántos fotogramas puede procesar el SoC por segundo. Un FPS más alto significa un análisis de video más suave y en tiempo real.
- Eficiencia energética (FPS/Watt):Se calcula dividiendo el rendimiento por la potencia consumida en vatios. Esta métrica es crucial para dispositivos alimentados por batería o con restricciones térmicas.
- Costo-Rendimiento (FPS/Dólar):Divide el rendimiento por el costo aproximado del módulo SoC. Esta métrica revela el valor financiero final del hardware.
BENCHMARKS DE PRODUCCIÓN (FPS)
El rendimiento, medido en cuadros por segundo (FPS), es la prueba definitiva de la capacidad de un SoC para manejar el análisis de video en tiempo real. Un FPS más alto indica un procesamiento más suave y la capacidad de ejecutar modelos más complejos sin demora. Esta sección presenta los resultados de nuestras pruebas de inferencia de visión por computadora, centrándose exclusivamente en la velocidad de procesamiento en bruto.
RENDIMIENTO DE HISILICON NPU
HiSilicon SoCs demuestran un rendimiento excepcional, un resultado directo de su dedicadoArquitectura NPU. El hardware está especialmente diseñado para las operaciones matemáticas centrales de las redes neuronales. Esta especialización conduce a un rendimiento consistentemente alto en varios modelos.
- FPS alto en modelos complejos:El HiSilicon NPU procesa modelos exigentes como YOLOv5 y ResNet-50 con una velocidad notable.
- Rendimiento estable:El rendimiento permanece estable incluso bajo carga continua, lo cual es crítico para aplicaciones como la videovigilancia 24/7.
- Manejo eficiente de datos:La memoria en el chip de la NPU y las rutas de datos optimizadas minimizan los cuellos de botella, permitiendo que los núcleos de procesamiento funcionen a su máximo potencial.
Este diseño enfocado permite que los SoC HiSilicon alcancen un nivel de rendimiento que el hardware de uso general lucha por igualar.
RENDIMIENTO SOC GENÉRICO
Los SoC genéricos, como los de Rockchip, ofrecen un rendimiento más variado. Su rendimiento depende en gran medida del modelo específico y del nivel de optimización del software. Si bien pueden lograr FPS impresionantes en modelos más simples y bien optimizados, su rendimiento a menudo disminuye drásticamente con redes neuronales más complejas.
El Rockchip RK3588, por ejemplo, muestra esta variabilidad claramente. Puede procesar modelos ligeros a más de 200 FPS. Sin embargo, su rendimiento en un modelo complejo como YOLOv8m-seg cae a menos de 5 FPS. Esta inconsistencia presenta un desafío significativo para los desarrolladores que crean aplicaciones de visión de alto rendimiento.
Esta brecha de rendimiento destaca la compensación de una arquitectura versátil. La CPU y la GPU deben combinar las tareas de IA con otros procesos del sistema, lo que limita su rendimiento de inferencia dedicado.
COMPARACIÓN DE FPS DE CABEZA A CABEZA
Una comparación directa revela la diferencia de rendimiento práctico entre el hardware especializado y de uso general. La siguiente tabla contrasta el FPS logrado por un HiSilicon SoC con una potente NPU contra el popular Rockchip RK3588. Todas las pruebas utilizaron la precisión INT8 para la máxima aceleración de hardware.
| Modelo | HiSilicon SoC (NPU) | Rockchip RK3588 (NPU) | Ganador de rendimiento |
|---|---|---|---|
| ResNet-50 | ~ 195 FPS | ~ 110 FPS | HiSilicon |
| YOLOv5m | ~ 90 FPS | ~ 45 FPS | HiSilicon |
Los resultados son claros. El SoC HiSilicon ofrece casi el doble de rendimiento en las tareas de clasificación de imágenes (ResNet-50) y detección de objetos (YOLOv5m). Esta ventaja proviene del motor de cubo 3D y la unidad de vectores de la NPU, que están diseñados específicamente para los tipos de cálculos que requieren estos modelos. Si bien el RK3588 es un chip capaz, su NPU no alcanza el mismo nivel de eficiencia. Para aplicaciones que exigen el FPS más alto posible, el hardware especializado proporciona una ventaja definitiva.
ANÁLISIS DE EFICIENCIA ENERGÉTICA
El rendimiento bruto es solo la mitad de la historia. Para dispositivos de borde,Eficiencia de potenciaEs igualmente importante. Un SoC que ofrece un alto FPS pero consume energía excesiva no es práctico para aplicaciones operadas por batería o restringidas térmicamente. Este análisis examina el consumo de energía de cada arquitectura y calcula el verdadero rendimiento por vatio.
POWER DRAW BAJO CARGA
Poder dibujarMide la energía que consume un SoC mientras realiza una tarea. Un menor consumo de energía es crítico para extender la vida útil de la batería y reducir el calor. Nuestras pruebas midieron el consumo de energía de cada SoC mientras ejecutaban una carga de trabajo de inferencia continua.
Los resultados muestran una clara ventaja para la arquitectura especializada. El SoC HiSilicon consume significativamente menos energía que el SoC Rockchip genérico para realizar la misma tarea. Esta eficiencia proviene de su NPU dedicada. La NPU maneja la carga de trabajo de IA, permitiendo que los núcleos principales de la CPU funcionen en un estado de bajo consumo. En contraste, el SoC genérico debe confiar más en su CPU y GPU hambrientas de energía, lo que lleva a un mayor consumo general.
La siguiente tabla muestra el consumo de energía aproximado en vatios para cada SoC cuando se ejecuta el modelo ResNet-50.
| SoC | Modelo | Consumo de potencia aproximado (vatios) |
|---|---|---|
| SoC HiSilicon | ResNet-50 | ~ 3,5 W |
| RK3588 Rockchip | ResNet-50 | ~ 5,0 W |
RENDIMIENTO POR VATIO (FPS/WATT)
El rendimiento por vatio es la métrica definitiva para la eficiencia. Revela cuánto rendimiento de procesamiento ofrece un SoC por cada vatio de potencia que consume. Una relación FPS/Watt más alta indica una eficiencia superior.
Calculamos este valor con una fórmula simple:
Rendimiento (FPS) /Consumo de energía (vatios) = Rendimiento por vatio (FPS/vatio)
La aplicación de esta fórmula a nuestros datos de referencia destaca la profunda eficiencia de la HiSilicon NPU.
Ventaja de eficiencia de HiSilicon El HiSilicon SoC ofrece más de55 FPS por cada vatioDe la potencia consumida. El Rockchip RK3588, mientras que es capaz, proporciona sólo 22 FPS por vatio. Esto significa que la arquitectura HiSilicon es más del doble de eficiente energéticamente para esta carga de trabajo.
La siguiente tabla desglosa el cálculo, combinando los datos de rendimiento de la sección anterior con los datos de potencia anteriores.
| SoC | Rendimiento (FPS) | Power Draw (W) | Rendimiento por vatio (FPS/W) |
|---|---|---|---|
| SoC HiSilicon | ~ 195 FPS | ~ 3,5 W | ~ 55,7 FPS/W |
| RK3588 Rockchip | ~ 110 FPS | ~ 5,0 W | ~ 22,0 FPS/W |
IMPLICACIONES DE EDGE COMPUTING
Excelente rendimiento por vatio tiene beneficios directos y prácticos para implementaciones de AI de borde. No es solo un número abstracto; afecta fundamentalmente el diseño del producto, la confiabilidad y el costo operativo.
Las implicaciones clave incluyen:
- Una vida de batería más larga:Para dispositivos móviles o alimentados por batería como drones, cámaras corporales y herramientas de diagnóstico portátiles, una mayor eficiencia se traduce directamente en un mayor tiempo operativo entre cargas.
- Reducción del estrangulamiento térmico:Menor consumo de energía genera menos calor. Esto permite diseños de productos más pequeños y sin ventilador y evita que el SoC se sobrecaliente y reduzca su rendimiento (regulación térmica).
- Presupuestos de energía más pequeños:Los SoC eficientes pueden funcionar con fuentes de alimentación más pequeñas y menos costosas. Esto reduce el costo total de la lista de materiales (BOM) para el producto final.
💡La eficiencia permite la innovación En última instancia, la eficiencia energética superior permite a los ingenieros construir dispositivos de IA de borde más pequeños, más confiables y más capaces. Mueve la visión por computadora de alto rendimiento desde el centro de datos a la palma de su mano.
ANÁLISIS COSTO-RENDIMIENTO
Las métricas de rendimiento proporcionan información técnica, pero el valor financiero a menudo impulsa las decisiones de hardware. Un SoC debe ofrecer un rendimiento sólido a un precio competitivo para ser una solución viable. Este análisis va más allá de la velocidad bruta para evaluar la rentabilidad de los SoC especializados frente a los de propósito general. Mide el retorno de la inversión para cada elección de hardware.
COMPARACIÓN DE COSTOS UNITARIOS
El precio de compra inicial es una consideración primordial para cualquier proyecto. SoC especializados como los de HiSilicon a menudo se perciben como caros. Sin embargo, una comparación directa muestra que son altamente competitivos con las opciones populares de propósito general. La siguiente tabla enumera los costos aproximados de los módulos principales utilizados en nuestros puntos de referencia.
| Módulo SoC | Coste unitario aproximado (a granel) |
|---|---|
| SoC HiSilicon | ~ $45 |
| RK3588 Rockchip | ~ $60 |
Estas cifras muestran que el módulo especializado de HiSilicon no solo es potente sino también más asequible que la alternativa genérica de gama alta. Esta ventaja de costo establece el escenario para una propuesta de valor impresionante.
CALCULAR FPS-PER-DOLLAR
Para cuantificar elValor financiero, Calculamos el FPS por dólar. Esta métrica revela cuánto rendimiento obtiene por cada dólar gastado en el módulo SoC. La fórmula es simple:
Rendimiento (FPS) /Costo del módulo ($) = FPS por dólar
La aplicación de esta fórmula a nuestros datos de referencia ResNet-50 demuestra una diferencia significativa en el valor.
| SoC | Rendimiento (FPS) | Costo ($) | FPS por dólar |
|---|---|---|---|
| SoC HiSilicon | ~ 195 FPS | ~ $45 | ~ 4,3 FPS/$ |
| RK3588 Rockchip | ~ 110 FPS | ~ $60 | ~ 1,8 FPS/$ |
HiSilicon SoC ofrece más del doble de rendimiento por cada dólar gastado. Esto lo convierte en el claro ganador para los desarrolladores que buscan maximizar el rendimiento con un presupuesto ajustado.
COSTO TOTAL DE LA PROPIEDAD
El precio inicial del hardware es solo una parte del panorama financiero.Coste total de propiedad(TCO) proporciona una visión más completa al incluir los gastos operativos y de desarrollo a largo plazo.
💡El TCO mira más allá del precio.Considera todos los costos a lo largo del ciclo de vida del producto, incluido el consumo de energía, los requisitos de refrigeración y el esfuerzo de ingeniería.
Un SoC especializado con una NPU dedicada ofrece varias ventajas de TCO:
- Costos de energía más bajos:La eficiencia energética superior reduce el consumo de electricidad durante la vida útil del producto.
- Costos reducidos de BOM:Menor producción de calor puede eliminar la necesidad de costosos ventiladores o disipadores de calor.
- Desarrollo más rápido:Una NPU bien soportada con una pila de software madura puede reducir el tiempo de ingeniería y acelerar el tiempo de comercialización.
Teniendo en cuenta estos factores, la arquitectura especializada HiSilicon presenta un caso convincente para un menor TCO en aplicaciones de visión exigentes.
Nuestras pruebas de inferencia de visión por computadora revelan una conclusión clara. HiSilicon SoCs, con sus NPUs especializadas, ofrecen rendimiento superior y eficiencia energética para aplicaciones de visión dedicadas. SoCs genéricos siguen siendo una opción viable para dispositivos multipropósito donde la visión no es la única prioridad. Ofrecen una mayor flexibilidad de desarrollo en diferentes plataformas.
Recomendación aplicable:Para los proyectos de visión de AI de borde crítico para el rendimiento, los SoC HiSilicon proporcionan el equilibrio mejor demostrado de rendimiento, potencia y costo. Para tareas menos exigentes o dispositivos de propósito general, SoC genéricos pueden ser suficientes.
Preguntas frecuentes
¿Por qué la HiSilicon NPU supera a los SoC genéricos?
HiSilicon NPUs contienenHardware especializadoComo un motor de cubo 3D. Esta arquitectura acelera directamente las matemáticas utilizadas en las redes neuronales. Procesa modelos de IA mucho más rápido y de manera más eficiente que los procesadores de propósito general, que deben manejar muchas tareas diferentes.
¿Son los SoC genéricos una mala elección para aplicaciones de visión?
En absoluto. SoC genéricos proporcionan una excelente versatilidad para dispositivos multipropósito. Son una opción viable cuando la visión por computadora no es la única prioridad o cuando se necesita la máxima flexibilidad de software para varias tareas.
¿Qué significa FPS/Watt alto para mi producto?
Una alta relación FPS/Watt afecta directamente el diseño del producto. Permite una mayor duración de la batería para dispositivos portátiles como drones. También reduce el calor, lo que permite carcasas más pequeñas y sin ventilador y evita que el SoC se ralentice (estrangulación térmica).
¿Es la precisión INT8 siempre la mejor opción para la inferencia?
La precisión INT8 ofrece la mejor velocidad y eficiencia energética, lo que la hace ideal para la mayoría de las tareas aceleradas por NPU. FP16 sigue siendo una opción fuerte. Proporciona un buen equilibrio cuando un modelo requiere una precisión numérica ligeramente superior para sus cálculos.





