

Elegir el acelerador AI de Ascend derecho para la inferencia de bordes
Te enfrentas a muchas opciones al seleccionar Ascend AI Accelerators para la inferencia de bordes. Debe satisfacer las necesidades de su aplicación para

Te enfrentas a muchas opciones al seleccionar Ascend AI Accelerators para la inferencia de bordes. Debe hacer coincidir las necesidades de rendimiento, potencia y coste de su aplicación con las características de hardware adecuadas. Edge AI está creciendo rápidamente. El mercado global alcanzado20.780 millones de dólaresEn 2024 con un 21,7% CAGR. Muchas aplicaciones ahora requieren tiempos de respuesta menores a 50 milisegundos. La inferencia de ai en tiempo real es importante para cámaras inteligentes, vehículos y robots. Ascend AI Accelerators funciona con sistemas edge y en la nube, lo que le brinda flexibilidad. Encontrarás muchos modelos. Cada uno se adapta a diferentes tareas, como análisis de imágenes, modelos de lenguaje grande o entornos difíciles.
| Métrica | Valor |
|---|---|
| 2024 Valoración | 20.780 millones de dólares |
| Tasa de crecimiento | 21,7% CAGR |
| Requisito de rendimiento | Tiempos de respuesta Sub-50ms |
Consejo: Concéntrese en su caso de uso y entorno para encontrar el mejor ajuste.
Puntos clave
- Identifique sus necesidades de aplicación primero. Concéntrese en el rendimiento, la potencia y el costo para elegir el acelerador Ascend AI correcto.
- Considere el factor de forma del acelerador. Seleccione un tamaño que se adapte a su entorno de implementación, ya sea compacto para drones o más grande para centros de datos.
- Evaluar la eficiencia energética. Elija aceleradores que minimicen el uso de energía para reducir los costos y prolongar la vida útil del dispositivo, especialmente para aplicaciones de vanguardia.
- ComprobarCompatibilidad con frameworks de software. Asegúrese de que sus modelos de IA funcionen sin problemas con herramientas populares como TensorFlow y PyTorch para evitar problemas de integración.
- Pruebe sus modelos AI en el hardware seleccionado. Este paso garantiza que el rendimiento cumpla con los requisitos de velocidad y precisión antes de la implementación completa.
Descripción general de Ascend AI Accelerators

Familia del producto
Puede encontrar muchas opciones en elAscend AI Accelerator alineación. Estas plataformas lo ayudan a ejecutar tareas ai en el borde y en la nube. Cada unoFamilia productoTiene un papel especial. Algunas plataformas se centran en la inferencia de borde, mientras que otras admiten cargas de trabajo de AI basadas en la nube.
| Familia del producto | Papel principal en la inferencia de Edge y Cloud |
|---|---|
| Procesadores Ascend AI | Capa de chip central en la pila completa, arquitectura escalable |
| Atlas AI computación | Proporciona varios factores de forma de producto para infraestructuras de IA |
| Módulo Atlas 200 AI | Diseñado para aplicaciones de borde |
| Tarjeta Atlas 300 AI | Utilizado en entornos de nube |
| Estación de Atlas 500 AI | Destina soluciones de computación de borde |
| Servidores de AI Atlas 800 | Admite aplicaciones de IA basadas en la nube |
Puede utilizar estas plataformas paraConstruir soluciones de ai flexibles. Los aceleradores Ascend ai le brindan el poder de procesar datos rápidamente. Puede elegir las plataformas adecuadas para sus necesidades, ya sea que desee ejecutar ai en el borde o en la nube.
Integración de Edge y Cloud
Los aceleradores Ascend ai funcionan bien con las plataformas edge y cloud. Puede implementar modelos ai en diferentes dispositivos y obtener resultados rápidos. Algunos aceleradores son pequeños y se adaptan a sistemas compactos. Otros trabajan en servidores grandes para cargas de trabajo pesadas de ai.
Estos son algunos modelos y dispositivos clave que puede usar para la inferencia de bordes:
- Ascend 310: Este chip forma parte de la gama Atlas. Puede usarlo para muchas aplicaciones ai.
- Atlas 200: Este módulo acelerador de ai compacto ofrece hasta16 teraflops de potencia informática. Utiliza sólo de 8 a 13,8 vatios.
- Atlas 500: esta solución de borde proporciona 16 teraflops (INT8) u 8 teraflops (FP16). Soporta procesamiento en tiempo real y utiliza de 25 a 40 vatios.
Puede mezclar y combinar estas plataformas para adaptarse a su proyecto. Los aceleradores Ascend ai lo ayudan a construir sistemas inteligentes que responden rápidamente. Puede ejecutar tareas ai en el borde para obtener resultados rápidos o enviar datos a la nube para un análisis más profundo.
Nota: Siempre debe comprobar la potencia y el rendimiento de cada acelerador antes de elegir una plataforma. Esto le ayuda a obtener los mejores resultados para su aplicación de ai.
Inferencia de AI en el borde

Inferencia en tiempo real
Necesita respuestas rápidas y confiables para muchas aplicaciones modernas. La inferencia de IA en el borde le permite procesar datos cerca de donde se crean. Este enfoque trae varios beneficios importantes:
- Procesamiento en tiempo real: Obtiene resultados inmediatos porque el dispositivo maneja los datos localmente. Esto es crítico para la inferencia de ai en tiempo real en cámaras inteligentes, vehículos autónomos y monitoreo de atención médica.
- Privacidad y seguridad: mantiene información confidencial en el dispositivo, lo que reduce el riesgo de fugas de datos durante la transmisión.
- Eficiencia de ancho de banda: envía menos datos a la nube, lo que ahorra recursos de red y reduce los costos. Esto ayuda en áreas remotas con conectividad limitada.
- Escalabilidad: puede agregar más dispositivos de borde a medida que crecen sus necesidades. Esto no sobrecarga sus sistemas centrales.
- Eficiencia energética: los dispositivos Edge utilizan menos energía porque evitan la transmisión constante de datos.
- Operación fuera de línea: su inferencia de ai puede seguir funcionando incluso si se cae la conexión a Internet.
Consejo: La inferencia de ai en tiempo real en el borde reduce la latencia. Usted obtiene decisiones más rápidas y mejores experiencias de usuario.
Aceleración de hardware
Puede aumentar el rendimiento de inferencia de ai conAceleración de hardware. Los chips especiales como las GPU manejan muchas tareas a la vez. Esto haceProcesamiento en tiempo realPosible para las cargas de trabajo exigentes ai. Esto se ve en la acción con el análisis de vídeo en tiempo real para la seguridad, el mantenimiento predictivo en las fábricas y los controles de calidad automatizados en la fabricación.
La aceleración de hardware le permite analizar los datos rápidamente y tomar decisiones sin esperar a los servidores en la nube. Esto reduce la latencia y mantiene su información privada. También mejora el uso de energía y admite más cargas de trabajo de IA en cada dispositivo. Con la optimización correcta, puede ejecutar tareas de inferencia complejas sin problemas y de manera confiable.
Nota: La aceleración de hardware es clave para la inferencia de ai en tiempo real. Le ayuda a cumplir con los estrictos requisitos de latencia y manejar cargas de trabajo pesadas de ai en el borde.
Criterios de selección
Elegir el acelerador Ascend AI correcto para la inferencia de bordes significa que debe tener en cuenta varios factores importantes. Desea asegurarse de que sus aplicaciones de IA funcionen sin problemas y cumplan sus objetivos de costo, eficiencia energética y rendimiento. Estos son los principales criterios que debes considerar:
Rendimiento
Necesita hacer coincidir el rendimiento del acelerador con sus aplicaciones de AI. Algunas tareas, como el análisis de imágenes o la inferencia de video, requieren una alta potencia informática. Otros, como el simpleSensorProcesamiento de datos, necesitan menos. Debe comprobar el número de teraflops,MemoriaAncho de banda y tipos de datos admitidos. La inferencia rápida ayuda a sus aplicaciones a responder en tiempo real. Si trabaja con modelos de lenguaje grandes o cargas de trabajo de AI complejas, necesita un acelerador con un rendimiento sólido. También debe observar qué tan bien el acelerador maneja múltiples tareas a la vez.
Sugerencia: Siempre pruebe sus modelos de ai en el hardware de destino para ver si la velocidad de inferencia cumple con sus requisitos.
Eficiencia energética
La eficiencia energética es crítica para las implementaciones de borde. Desea que sus aplicaciones de AI funcionen durante largos períodos sin sobrecalentarse o agotar las baterías. El Ascend 910C destaca por su eficiencia energética. Se utiliza sobre310W, Lo que ayuda a reducir el costo total de propiedad. Otros aceleradores, como el NVIDIA H100, ofrecen más rendimiento en bruto pero usan mucha más energía. Debe comparar el uso de energía de cada acelerador y elegir uno que se ajuste a sus necesidades de implementación. Un consumo de energía más bajo significa menos calor y una vida más larga del dispositivo.
- Ascend 910C ofrece una gran eficiencia energética para la inferencia de bordes.
- Un menor uso de energía ayuda a reducir los costos y admite aplicaciones de IA sostenibles.
- La alta eficiencia energética significa que puede implementar más dispositivos sin aumentar su presupuesto de energía.
Factor de forma
El factor de forma del acelerador afecta dónde puede implementar sus aplicaciones de ai. Debe elegir un tamaño y forma que se adapte a su entorno. Algunos aceleradores son pequeños y ligeros, perfectos para drones o cámaras. Otros son más grandes y funcionan mejor en servidores Edge o centros de datos. La siguiente tabla muestra diferentes factores de forma y su impacto en la implementación:
| Factor de forma | Descripción | Impacto del despliegue |
|---|---|---|
| Acelerador Atlas 200 AI | Módulo compacto, la mitad del tamaño de una tarjeta de crédito,Consumo de energía de 10 vatios | Ideal para dispositivos como cámaras y drones, que permiten análisis de video HD en tiempo real. |
| Acelerador Atlas 300 AI | Tarjeta estándar PCIe HHHL para centros de datos y servidores Edge | Admite múltiples precisiones de datos, ofreciendo alto rendimiento para tareas de aprendizaje profundo e inferencia. |
| Estación de borde Atlas 500 AI | Integra el procesamiento de AI en un tamaño de decodificador | Adecuado para diversas aplicaciones, incluyendo el transporte y la asistencia sanitaria, con importantes mejoras de rendimiento. |
| Aparato Atlas 800 AI | Entorno de IA optimizado con software preinstalado | Listo para usar rápidamente, integra el software de administración para aplicaciones empresariales de IA, reduciendo las barreras de entrada. |
Debe elegir un factor de forma que coincida con su espacio de implementación y las necesidades de sus aplicaciones de AI.
Coste
El costo es un factor importante cuando selecciona un acelerador para la inferencia de bordes. Necesita mirar el precio del hardware, el costo de energía y el costo de mantenimiento. Algunos aceleradores cuestan más por adelantado, pero ahorran dinero con el tiempo debido a una mejor eficiencia energética. El Ascend 910C, por ejemplo, ofrece una buena eficiencia energética, lo que reduce el costo total de propiedad. También debe considerar el costo de las licencias de software y el soporte. Si planea escalar sus aplicaciones de IA, debe pensar en el costo de agregar más aceleradores.
- El costo del hardware afecta su presupuesto para aplicaciones de AI.
- El costo de la energía afecta el ahorro a largo plazo.
- El costo de mantenimiento incluye actualizaciones y reparaciones.
- El costo total de propiedad combina todos estos factores.
Nota: Calcule siempre el costo total antes de decidirse por un acelerador. Esto le ayuda a evitar sorpresas y mantiene sus aplicaciones de AI funcionando sin problemas.
Compatibilidad
La compatibilidad con su hardware y software existente es esencial. Desea que sus aplicaciones de AI funcionen con marcos populares como TensorFlow y PyTorch. Las plataformas Ascend son compatibles con estos marcos, lo que facilita la integración. Huawei tieneCANN de código abiertoPara ayudar a los desarrolladores a alejarse de los fabricantes de chips occidentales. El ecosistema sigue creciendo, por lo que puede enfrentar algunos desafíos. Huawei también proporciona adaptadores para los modelos PyTorch en las NPUs Ascend. Este enfoque en la interoperabilidad lo ayuda a cambiar sin perder el soporte para sus aplicaciones de AI. MindSpore ofrece otra opción para construir y administrar cargas de trabajo ai.
- Ascend es compatible con TensorFlow, PyTorch y MindSpore para aplicaciones ai.
- Las herramientas de código abierto le ayudan a migrar sus cargas de trabajo de inferencia.
- La compatibilidad reduce el coste de integración y acelera la implementación.
Consejo: Compruebe la compatibilidad de sus modelos y software de ai antes de elegir un acelerador. Esto le ahorra tiempo y costos durante la implementación.
Coincidencia de los requisitos de la aplicación
Siempre debe hacer coincidir los criterios de selección con sus aplicaciones de ai específicas. Si trabaja con análisis de imágenes o de vídeo, necesita un alto rendimiento y eficiencia energética. Para modelos de lenguaje grandes, necesita más memoria y potencia informática. Las condiciones ambientales también importan. Algunos aceleradores funcionan mejor en lugares duros o remotos. Debe enumerar sus requisitos y compararlos con las características de cada acelerador.
- La inferencia en tiempo real para cámaras y drones necesita aceleradores compactos y energéticamente eficientes.
- Las aplicaciones de salud y transporte pueden necesitar factores de forma más grandes y un mayor rendimiento.
- El costo y la compatibilidad afectan la rapidez con la que puede implementar y escalar sus aplicaciones de AI.
Recuerde: el mejor acelerador para su inferencia de bordes depende de las necesidades de su aplicación, los límites de costos, los objetivos de eficiencia energética y la compatibilidad con sus sistemas existentes.
Comparación de modelos
Elegir el Ascend AI Accelerator correcto para la inferencia de bordes significa comprender lo que ofrece cada modelo. Desea combinar su aplicación con el mejor hardware. Veamos cuatro opciones populares: Ascend 310, Ascend 910C, Atlas 200 y Atlas 500 Pro.
Ascender 310
Ascend 310 le ofrece un equilibrio entre rendimiento y eficiencia. Puedes usarlo en muchos escenarios de borde ai. Este chip funciona bien en dispositivos pequeños y admite el procesamiento en tiempo real. Se encarga de hasta200 caras u objetosA la vez, lo que lo hace ideal para la seguridad y la supervisión.
| Caso de uso | Descripción |
|---|---|
| Cámaras de seguridad | Procesa 200 caras u objetos al mismo tiempo. Perfecto para monitoreo en tiempo real. |
| Drones | Aumenta las características autónomas y admite varias tareas de ai. |
| Venta minorista autónoma inteligente | Potencia las soluciones impulsadas por AI en el comercio minorista, mejorando la experiencia y la eficiencia del cliente. |
| Monitoreo del sitio de construcción | Ayuda a las empresas de construcción a realizar un seguimiento de las actividades in situ. |
| Monitoreo de línea eléctrica | Permítenos a los proveedores de servicios públicos monitorear las líneas eléctricas de manera eficiente. |
Puede implementar Ascend 310 en lugares donde necesita una inferencia de ai rápida pero tiene espacio o potencia limitados. Encaja bien en cámaras inteligentes, drones y sistemas minoristas.
Ascender 910C
Ascend 910C destaca por su alta potencia computacional y eficiencia energética. Te levanta a320 TFLOPS de rendimiento FP16. Este chip usa aproximadamente 310 vatios, que es más bajo que muchas GPU de la competencia. Funciona bien para aprendizaje profundo y modelos de ai grandes.
| Métrica | Ascender 910C | NVIDIA NVL72 B200 |
|---|---|---|
| Consumo de energía (por GPU) | 70%-80% de NVIDIA NVL72 | 100% |
| Rendimiento general de supernodo (FLOPS) | 70% más alto que NVL72 | 100% |
| Consumo de energía por FLOP | 2,3 veces superior | 1,0 |
| Ancho de banda de la memoria Consumo de energía por TB/s | 1,8 veces más alto | 1,0 |
| Capacidad de memoria Consumo de energía por TB de HBM | 1,1 veces más alto | 1,0 |
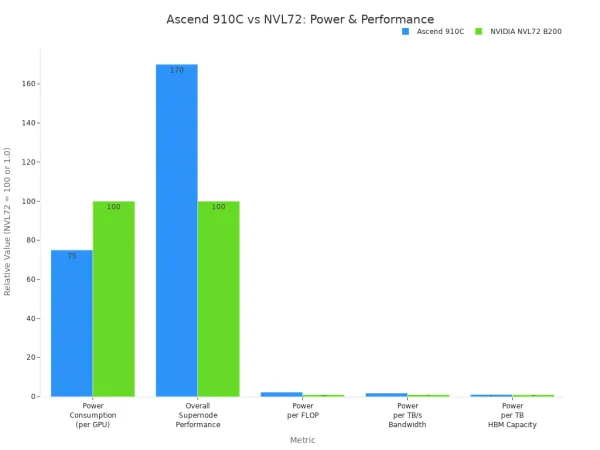
Puede usar Ascend 910C para cargas de trabajo de ai exigentes. Se adapta mejor a servidores perimetrales o centros de datos donde necesita un rendimiento sólido y menores costos de energía. Este modelo es ideal para entrenar y ejecutar modelos ai grandes en tiempo real.
Nota: Ascend 910C compite con las mejores GPU como NVIDIA A100 y H100. Usted obtiene un alto rendimiento y ahorra energía.
Atlas 200
El atlas 200 es un módulo compacto del acelerador del ai. Se trata deLa mitad del tamaño de una tarjeta de crédito. Puede usarlo en dispositivos terminales como cámaras, robots y drones. Este módulo admite análisis de video HD en tiempo real de 16 canales. Usted obtiene un fuerte procesamiento de ai en un paquete pequeño.
- Puede implementar Atlas 200 en cámaras para vigilancia inteligente.
- Funciona bien en robots para la toma de decisiones en tiempo real.
- Los drones utilizan Atlas 200 para la navegación y el monitoreo impulsado por AI.
El atlas 200 maneja ambientes duros. Trabaja en temperaturas de-20 °C a 55 °C y puede manejar choques y vibraciones. Esto lo convierte en una buena opción para aplicaciones de AI al aire libre o móviles.
| Factor ambiental | Especificación |
|---|---|
| Temperatura de almacenamiento | De 30 a 60 °C |
| Temperatura de funcionamiento | -20 a 55 °C ambiente |
| Humedad | Funcionamiento: 20% ~ 80%, relativo, sin condensación |
| Prueba | Estándar | Parámetros |
|---|---|---|
| Choque | DIN EN 60068-2-27 | Cada eje (x/y/z), 20g, 11ms, /- 10 choques |
| Bump (en inglés) | DIN EN 60068-2-27 | Cada eje (x/y/z), 20g, 11ms, /- 100 golpes |
| Vibración (aleatoria) | DIN EN 60068-2-64 | Cada eje (x/y/z), 4,9g rms, 15-500Hz, aceleración de 0,05g 2/Hz, 30min por eje |
| Vibración (sinusoidal) | DIN EN 60068-2-6 | Cada eje (x/y/z), 10-58Hz: 1,5mm, 58-500Hz: 10g, 1 oct/min, 1 hora 52 min por eje |
Consejo: Atlas 200 es una buena opción para ai at the edge, especialmente en entornos hostiles o móviles.
Para Atlas 500 Pro
Atlas 500 Pro le ofrece una potente solución de ai de borde en un tamaño de caja de set-top. Puede usarlo para análisis de video en tiempo real, transporte inteligente y atención médica. Este dispositivo admite hasta 16 teraflops (INT8) u 8 teraflops (FP16) de potencia de cálculo. Utiliza entre 25 y 40 vatios, lo que lo hace eficiente energéticamente.
Puede implementar Atlas 500 Pro en lugares donde necesita un fuerte rendimiento de ai pero no tiene espacio para servidores grandes. Se adapta bien a proyectos de ciudades inteligentes, hospitales y centros de transporte. Usted obtiene una inferencia de ai confiable y una fácil integración con los sistemas existentes.
Puntos fuertes de Atlas 500 Pro:
- Ofrece alto rendimiento ai para aplicaciones de borde.
- Admite análisis en tiempo real para datos de vídeo y sensores.
- Funciona en entornos donde el espacio y la potencia son limitados.
Llamada: Atlas 500 Pro le ayuda a llevar la ai avanzada al borde sin la necesidad de hardware voluminoso.
Cuando comparas estos modelos, ves que cada uno se ajusta a diferentes necesidades. Ascend 310 y Atlas 200 funcionan mejor en dispositivos pequeños, móviles o al aire libre. Ascend 910C y Atlas 500 Pro le dan más potencia para implementaciones de borde más grandes. Debe hacer coincidir su aplicación de ai con el modelo correcto para obtener los mejores resultados.
Optimización
Compresión modelo
Puede hacer que sus modelos ai funcionen más rápido y usar menos memoria utilizando técnicas de compresión de modelos. Estos métodos le ayudan a implementar ai en el borde donde los recursos son limitados. Dos técnicas populares son:
- Cuantificación: Este método reduce la precisión de los pesos del modelo. Se obtienen modelos más pequeños y una inferencia más rápida.
- Destilación del conocimientoEntrenas a un modelo más pequeño para que aprenda de uno más grande. El modelo más pequeño mantiene un buen rendimiento pero necesita menos recursos.
La destilación de conocimiento le permite reducir sus modelos ai. Transfieres el conocimiento de un modelo de maestro grande a un modelo de estudiante pequeño. Este proceso le ayuda a ahorrar memoria y acelerar la inferencia en los dispositivos de borde.
Debes probar estas técnicas si quieres que tus aplicaciones de AI funcionen bien en dispositivos pequeños.
Administración de energía
Necesitas administrar la potencia con cuidado cuando corres ai en el borde. Dispositivos como cámaras ySensoresA menudo tienen una vida útil limitada de la batería. Puede usar modos de ahorro de energía y programar tareas de ai durante períodos de baja actividad. Algunos aceleradores de Ascend AI admiten escalado dinámico de voltaje y frecuencia. Esta característica le permite ajustar el uso de energía en función de la carga de trabajo. También puede controlar la temperatura y el uso de energía para evitar el sobrecalentamiento. Una buena administración de energía lo ayuda a mantener sus sistemas de IA funcionando por más tiempo y de manera más confiable.
Consejo: La administración inteligente de energía significa que sus dispositivos de ai duran más y funcionan mejor en entornos difíciles.
Soporte de software
Tiene muchos marcos de software y herramientas para ayudarlo a implementar ai en Ascend AI Accelerators. Estas herramientas hacen que sea más fácil construir, probar y optimizar sus modelos.La siguiente tabla muestra algunas opciones populares:
| Marco/Herramienta | Descripción |
|---|---|
| Por PyTorch | Un marco gráfico computacional dinámico ideal para prototipos rápidos y experimentación. |
| TensorFlow | Un sistema versátil de aprendizaje automático que admite múltiples idiomas, ampliamente utilizado para diversas tareas. |
| MindSpore (en inglés) | El marco de código abierto de Huawei optimizado para los procesadores Ascend AI, mejorando el rendimiento a través del diseño conjunto. |
| Apache MXNet | Marco de aprendizaje profundo de AWS que admite múltiples lenguajes de programación. |
| Caffe | Un marco modular desarrollado para una fácil extensión de nuevos formatos de datos y capas de red. |
| Inferencia Deepytorch | Un acelerador de inferencia para los modelos PyTorch, mejorando el rendimiento a través de técnicas avanzadas. |
| MindStudio 2,0 | Una herramienta integral para el desarrollo integral de IA, simplificando el proceso para los desarrolladores. |
Puede elegir el marco que mejor se adapte a su proyecto. MindSpore funciona bien con procesadores Ascend y le da un rendimiento extra. PyTorch y TensorFlow son buenas opciones si quieres flexibilidad y apoyo de la comunidad. MindStudio 2,0 le ayuda a administrar su desarrollo de AI de principio a fin.
Lista de verificación de decisiones
Coincidencia de requisitos
Debe asegurarse de que los requisitos de su aplicación se ajusten a las características del Ascend AI Accelerator. Comience enumerando lo que necesita su proyecto. Piense en la velocidad, la potencia, el tamaño, el costo y el soporte de software. Utilice la lista de verificación a continuación para guiar su decisión:
- Rendimiento¿Necesita su aplicación análisis rápido de imágenes o de vídeo? Compruebe los teraflops y el ancho de banda de la memoria.
- Eficiencia energética¿Su dispositivo funcionará con batería o en un lugar con energía limitada? Busque modelos de baja potencia.
- Factor de forma¿Necesita su proyecto un módulo pequeño o una estación de borde más grande? Haga coincidir el tamaño con el espacio de implementación.
- Coste: ¿Puede permitirse elHardware y mantenimiento¿? Calcule el costo total, incluida la energía y el soporte.
- Compatibilidad¿Funcionará su software con los frameworks Ascend como TensorFlow, PyTorch o MindSpore? Asegúrese de que sus modelos funcionen sin problemas.
Consejo: Escriba sus tres requisitos principales. Úselos para comparar cada modelo de Ascend. Esto le ayuda a centrarse en lo que más importa para su proyecto.
| Requisito | Ejemplo Necesidad | Función de Ascend para que coincida |
|---|---|---|
| Velocidad | Vídeo en tiempo real | Alta TFLOPS, memoria rápida |
| Potencia | Operación de la batería | Baja potencia, chip eficiente |
| Tamaño | Drone o cámara | Módulo compacto |
| Coste | Límite presupuestario | Bajo TCO, ahorro de energía |
| Software | Soporte técnico de PyTorch | Compatibilidad con el marco |
Pasos de selección
Sigue estos pasos para elegir e implementar tu Ascend AI Accelerator:
- Defina los objetivos de su aplicación. Escribe lo que quieres que haga tu sistema AI.
- Enumere sus necesidades técnicas. Incluye velocidad, potencia, tamaño, costo y software.
- Comparar modelos Ascend. Use su lista de verificación para que coincida con las características de cada modelo.
- Prueba tu modelo AIEn el hardware seleccionado. Compruebe si cumple con sus objetivos de velocidad y precisión.
- Revisión de potencia y coste. Asegúrese de que el dispositivo se ajuste a su presupuesto y plan de energía.
- Comprobar la compatibilidad del software. Confirme que sus marcos y herramientas funcionan con el acelerador.
- Planificar el despliegue. Decida dónde y cómo va a instalar el dispositivo.
- Supervisar el rendimiento. Realice un seguimiento de los resultados y ajuste la configuración para obtener la mejor eficiencia.
Nota: Puede repetir estos pasos para cada proyecto nuevo. Este proceso te ayuda a elegir el acelerador correcto cada vez.
Mejorará la inferencia de bordes cuando coincida con las necesidades de su aplicación con el acelerador Ascend AI correcto. Verá un entrenamiento más rápido, modelos más simples y mejores tasas de detección.
| Característica | Descripción |
|---|---|
| Tiempo de entrenamiento | Reducción del 75% |
| Velocidad de inferencia | Aumento del 32,99% |
| Detección mAP | 97,1% |
Utilice esta lista de verificación:
- Enumere sus necesidades de velocidad y potencia.
- Elija un modelo que se ajuste a su presupuesto.
- Compruebe el soporte de software.
- Plan para futuras actualizaciones.
Manténgase actualizado a medida que evoluciona Edge AI. Las nuevas tendencias como los coprocesadores de IA, 5G e IoT siguen cambiando lo que puede hacer.
Preguntas frecuentes
¿Qué es un Acelerador Ascend AI?
Utiliza un Ascend AI Accelerator para acelerar las tareas de AI. Ayuda a su dispositivo a procesar datos rápidamente. Usted obtiene un mejor rendimiento para cosas como el análisis de imágenes y el monitoreo de video.
¿Cómo sé qué modelo de Ascend se ajusta a mi proyecto?
Enumere sus necesidades de velocidad, potencia, tamaño y costo. Usted compara estas necesidades con las características de cada modelo. Usted elige el modelo que mejor se adapte a sus necesidades.
Consejo: Anote sus tres necesidades principales antes de elegir.
¿Puedo ejecutar PyTorch o TensorFlow en dispositivos Ascend?
Puede ejecutar PyTorch y TensorFlow en la mayoría de los dispositivos Ascend. Huawei proporciona adaptadores y herramientas de código abierto. UstedComprobar compatibilidadAntes de desplegar sus modelos AI.
| Marco | ¿Apoyado en Ascend? |
|---|---|
| Por PyTorch | ✅ |
| TensorFlow | ✅ |
| MindSpore (en inglés) | ✅ |
¿Los aceleradores Ascend AI funcionan en entornos hostiles?
Puedes usar algunosModelos Ascend, Como Atlas 200, en condiciones difíciles. Estos dispositivos manejan el calor, el frío, los golpes y las vibraciones. Verifica las especificaciones de cada modelo para asegurarse de que se ajuste a su entorno.
- Atlas 200: Trabaja desde-20 °C hasta 55 °C
- Maneja choques y golpes





