

エッジ推論のための適切なAscend AIアクセラレータの選択
エッジ推論のためにAscend AIアクセラレータを選択するとき、あなたは多くの選択肢に直面します。アプリケーションのニーズと一致する必要があります。

エッジ推論のためにAscend AIアクセラレータを選択するとき、あなたは多くの選択肢に直面します。適切なハードウェア機能を使用して、パフォーマンス、パワー、およびコストに対するアプリケーションのニーズを一致させる必要があります。エッジAIは急速に成長しています。世界市場に到達207.8億ドル2024年に21.7% のCAGRで。現在、多くのアプリケーションでは、50ミリ秒未満の応答時間が必要です。リアルタイムAI推論は、スマートカメラ、車両、およびロボットにとって重要です。Ascend AIアクセラレータは、エッジシステムとクラウドシステムの両方で動作し、柔軟性を提供します。あなたは多くのモデルを見つけるでしょう。それぞれが、画像分析、大言語モデル、または厳しい環境などのさまざまなタスクに適合します。
| メトリック | 値 |
|---|---|
| 2024年の評価 | 207.8億ドル |
| 成長率 | 21.7% CAGR |
| パフォーマンス要件 | Sub-50ms応答時間 |
ヒント: 最適なものを見つけるために、ユースケースと環境に焦点を当てます。
重要なポイント
- 最初にアプリケーションのニーズを特定します。パフォーマンス、パワー、コストに重点を置いて、適切なAscend AIアクセラレータを選択します。
- アクセラレータのフォームファクタを考えてみましょう。ドローンの場合はコンパクトであろうと、データセンターの場合はそれ以上であろうと、デプロイ環境に合ったサイズを選択します。
- 電力効率の評価を使用します。エネルギー使用量を最小限に抑えるアクセラレータを選択して、特にエッジアプリケーションでコストを削減し、デバイスの寿命を延ばします。
- チェックソフトウェアフレームワークとの互换性を使用します。AIモデルがTensorFlowやPyTorchなどの一般的なツールとシームレスに連携し、統合の問題を回避できるようにします。
- 選択したハードウェアでAIモデルをテストします。この手順により、完全にデプロイする前に、パフォーマンスが速度と精度の要件を満たしていることが保証されます。
Ascend AIアクセラレータの概要

製品ファミリー
で多くのオプションを見つけることができますAIAcceleratorラインナップをAscendを使用します。これらのプラットフォームは、エッジとクラウドでaiタスクを実行するのに役立ちます。各制品ファミリー特別な役割があります。一部のプラットフォームはエッジ推論に重点を置いていますが、他のプラットフォームはクラウドベースのaiワークロードをサポートしています。
| 製品ファミリー | エッジとクラウドの推論における主な役割 |
|---|---|
| Ascend AIプロセッサ | フルスタックのスケーラブルなアーキテクチャのコアチップレイヤー |
| アトラスAIコンピューティング | AIインフラストラクチャにさまざまな製品フォームファクタを提供 |
| アトラス200 AIモジュール | エッジアプリケーション向けに設計 |
| アトラス300 AIカード | クラウド環境で使用 |
| アトラス500 AIステーション | エッジコンピューティングソリューションをターゲット |
| Atlas 800 AIサーバー | クラウドベースのAIアプリケーションをサポート |
これらのプラットフォームを使用して、柔軟なaiソリューションを構築するを使用します。Ascend aiアクセラレータは、データを迅速に処理する力を与えます。エッジでもクラウドでも、aiを実行するかどうかにかかわらず、ニーズに合った適切なプラットフォームを選択できます。
エッジとクラウドの統合
Ascend aiアクセラレータは、エッジプラットフォームとクラウドプラットフォームの両方でうまく機能します。Aiモデルをさまざまなデバイスにデプロイして、迅速な結果を得ることができます。一部のアクセラレータは小さく、コンパクトなシステムに適合します。他の人は重いaiワークロードのために大きなサーバーで働きます。
エッジ推論に使用する可能性のあるいくつかの重要なモデルとデバイスを次に示します。
- Ascend 310: このチップはAtlasの範囲の一部です。多くのaiアプリケーションに使用できます。
- Atlas 200: このコンパクトなaiアクセラレータモジュールは、最大16テラフロップのコンピューティングパワーを使用します。それは8から13.8ワットだけを使用します。
- アトラス500: このエッジソリューションは、16テラフロップ (INT8) または8テラフロップ (FP16) を提供します。リアルタイム処理をサポートし、25〜40ワットを使用します。
これらのプラットフォームを組み合わせて、プロジェクトに合わせて組み合わせることができます。Ascend aiアクセラレータは、迅速に対応するスマートシステムの構築に役立ちます。エッジでaiタスクを実行して迅速な結果を得るか、クラウドにデータを送信してより深い分析を行うことができます。
注: プラットフォームを選択する前に、各アクセラレータのパワーとパフォーマンスを常に確認する必要があります。これは、aiアプリケーションに最適な結果を得るのに役立ちます。
エッジでのAI推論

リアルタイム推論
最新の多くのアプリケーションでは、高速で信頼性の高い応答が必要です。エッジでのAI推論により、作成された場所に近いデータを処理できます。このアプローチはいくつかの重要な利点をもたらします。
- リアルタイム処理: デバイスがデータをローカルで処理するため、すぐに結果が得られます。これは、スマートカメラ、自動運転車、およびヘルスケアモニタリングにおけるリアルタイムの推論にとって重要です。
- プライバシーとセキュリティ: 機密情報をデバイスに保持するため、送信中のデータ漏洩のリスクが低くなります。
- 帯域幅効率: クラウドへの送信データが少なくなるため、ネットワークリソースが節約され、コストが削減されます。これは、接続が制限された遠隔地で役立ちます。
- スケーラビリティ: ニーズが高まるにつれて、エッジデバイスを追加できます。これは中央システムに過負荷をかけません。
- エネルギー効率: エッジデバイスは、一定のデータ伝送を回避するため、使用する電力が少なくなります。
- オフライン操作: インターネット接続が切断されても、aiの推論は機能し続けることができます。
ヒント: エッジでのリアルタイムのai推論により、レイテンシが短縮されます。より迅速な意思決定とより良いユーザーエクスペリエンスが得られます。
ハードウェアアクセラレーション
を使用してai推論パフォーマンスを向上させることができますハードウェア高速化を使用します。GPUのような特別なチップは、一度に多くのタスクを処理します。これは作るリアルタイム処理要求の厳しいaiワークロードで可能です。これは、セキュリティのためのリアルタイムビデオ分析、工場での予測メンテナンス、および製造における自動品質チェックで実際に行われていることがわかります。
ハードウェアアクセラレーションにより、クラウドサーバーを待たずにデータを迅速に分析し、決定を下すことができます。これにより、待ち時間が短縮され、情報が非公開になります。また、エネルギー使用量を改善し、各デバイスでより多くのaiワークロードをサポートします。適切な最適化により、複雑な推論タスクをスムーズかつ確実に実行できます。
注: ハードウェアアクセラレーションは、リアルタイムのai推論にとって重要です。厳密な遅延要件を満たし、エッジで重いaiワークロードを処理するのに役立ちます。
選択基準
エッジ推論に適したAscend AIアクセラレータを選択すると、いくつかの重要な要素を検討する必要があります。Aiアプリケーションをスムーズに実行し、コスト、エネルギー効率、パフォーマンスの目標を達成する必要があります。考慮すべき主な基準は次のとおりです。
パフォーマンス
アクセラレータのパフォーマンスをaiアプリケーションに合わせる必要があります。画像分析やビデオ推論などの一部のタスクには、高い計算能力が必要です。その他、シンプルなどセンサーデータ処理、より少ない必要性。あなたはテラフロップの数を確認する必要があります、メモリ帯域幅、およびサポートされているデータ型。高速推論は、アプリケーションがリアルタイムで応答するのに役立ちます。大規模な言語モデルや複雑なaiワークロードを使用する場合は、強力なパフォーマンスを備えたアクセラレータが必要です。また、アクセラレータが複数のタスクを一度にどれだけうまく処理するかを確認する必要があります。
ヒント: 常にターゲットハードウェアでaiモデルをテストして、推論速度が要件を満たしているかどうかを確認します。
パワー効率
エネルギー効率は、エッジ展開にとって重要です。バッテリーを過熱したり消耗させたりすることなく、aiアプリケーションを長期間実行する必要があります。Ascend 910Cは、その電力効率で際立っています。それはについて使用します310W、これは総所有コストを下げるのに役立ちます。NVIDIA H100のような他のアクセラレータは、より生のパフォーマンスを提供しますが、より多くのエネルギーを使用します。各アクセラレータのエネルギー使用量を比較し、展開のニーズに合ったアクセラレータを選択する必要があります。エネルギー消費量が少ないということは、熱が少なく、デバイスの寿命が長いことを意味します。
- Ascend 910Cは、エッジ推論のための強力なエネルギー効率を提供します。
- エネルギー使用量を減らすと、コストを削減し、持続可能なaiアプリケーションをサポートします。
- エネルギー効率が高いため、エネルギー予算を増やすことなく、より多くのデバイスを展開できます。
フォームファクター
アクセラレータのフォームファクタは、aiアプリケーションをデプロイできる場所に影響します。あなたはあなたの環境に合ったサイズと形を選ぶ必要があります。一部の加速器は小型で軽量で、ドローンやカメラに最適です。他のものはより大きく、エッジサーバーまたはデータセンターで最もよく機能します。以下の表は、さまざまなフォームファクタとそのデプロイへの影響を示しています。
| フォームファクター | 説明 | デプロイの影響 |
|---|---|---|
| アトラス200 AIアクセラレータ | コンパクトモジュール、クレジットカードの半分のサイズ、10ワット消费电力 | カメラやドローンなどのデバイスに最適で、リアルタイムのHDビデオ分析を可能にします。 |
| アトラス300 AIアクセラレータ | データセンターおよびエッジサーバー用のHHHL PCIe標準カード | 複数のデータ精度をサポートし、ディープラーニングと推論タスクに高いパフォーマンスを提供します。 |
| アトラス500 AIエッジステーション | AI処理をセットトップボックスサイズで統合 | 輸送やヘルスケアを含むさまざまなアプリケーションに適しており、パフォーマンスが大幅に向上します。 |
| Atlas 800 AIアプライアンス | ソフトウェアがプリインストールされた最適化AI環境 | 迅速に使用する準備ができて、エンタープライズAIアプリケーション用の管理ソフトウェアを統合し、参入障壁を減らします。 |
展開スペースとaiアプリケーションのニーズに一致するフォームファクタを選択する必要があります。
コスト
エッジ推論用のアクセラレータを選択すると、コストが大きな要因になります。ハードウェアの価格、エネルギーコスト、およびメンテナンスコストを確認する必要があります。一部の加速器は前払いでコストが高くなりますが、エネルギー効率が向上するため、時間の経過とともにコストを節約できます。たとえば、Ascend 910Cは優れた電力効率を提供し、総所有コストを削減します。また、ソフトウェアライセンスとサポートのコストも考慮する必要があります。Aiアプリケーションを拡張する場合は、アクセラレータを追加するコストについて考える必要があります。
- ハードウェアコストは、aiアプリケーションの予算に影響します。
- エネルギーコストは長期的な節約に影響を与えます。
- メンテナンス費用には、更新と修理が含まれます。
- 総所有コストは、これらすべての要因を組み合わせたものです。
注: アクセラレータを決定する前に、常に総コストを計算してください。これにより、驚きを回避し、aiアプリケーションをスムーズに実行できます。
互換性
既存のハードウェアとソフトウェアとの互换性が不可欠です。AiアプリケーションをTensorFlowやPyTorchなどの一般的なフレームワークで動作させる必要があります。Ascendプラットフォームはこれらのフレームワークをサポートしているため、統合が容易になります。HuaweiはオープンソースのCANN開発者が西洋のチップメーカーから離れるのを助けるために。生態系はまだ成長しているので、いくつかの課題に直面する可能性があります。Huaweiは、Ascend NPUのPyTorchモデル用のアダプターも提供しています。相互運用性に重点を置くことで、aiアプリケーションのサポートを失うことなく切り替えることができます。MindSporeは、aiワークロードを構築および管理するための別のオプションを提供します。
- Ascendは、aiアプリケーション向けにTensorFlow、PyTorch、およびMindSporeをサポートしています。
- オープンソースツールは、推論ワークロードの移行に役立ちます。
- 互換性により、統合コストが削減され、展開が高速化されます。
ヒント: アクセラレータを選択する前に、aiモデルとソフトウェアの互換性を確認してください。これにより、デプロイ中の時間とコストを節約できます。
アプリケーション要件の一致
選択基準を特定のaiアプリケーションに常に一致させる必要があります。画像またはビデオ分析を使用する場合は、高いパフォーマンスとエネルギー効率が必要です。大規模な言語モデルでは、より多くのメモリと計算能力が必要です。環境条件も重要です。一部のアクセラレータは、過酷な場所や遠隔地でよりよく機能します。要件をリストし、それらを各アクセラレータの機能と比較する必要があります。
- カメラとドローンのリアルタイム推論には、コンパクトでエネルギー効率の高い加速器が必要です。
- ヘルスケアおよび輸送アプリケーションには、より大きなフォームファクターとより高いパフォーマンスが必要になる場合があります。
- コストと互換性は、aiアプリケーションのデプロイとスケールの速さに影響します。
注意: エッジ推論に最適なアクセラレーターは、アプリケーションのニーズ、コスト制限、エネルギー効率の目標、および既存のシステムとの互換性によって異なります。
モデル比較
エッジ推論のために適切なAscend AIアクセラレータを選択することは、各モデルが提供するものを理解することを意味します。アプリケーションを最高のハードウェアと一致させたい。Ascend 310、Ascend 910C、Atlas 200、およびAtlas 500 Proの4つの一般的なオプションを見てみましょう。
ステップ310
Ascend 310は、パフォーマンスと効率のバランスを提供します。多くのエッジaiシナリオで使用できます。このチップは小型デバイスでうまく機能し、リアルタイム処理をサポートします。それはまで扱います200面またはオブジェクト一度に、セキュリティと監視に最適です。
| ユースケース | 説明 |
|---|---|
| 防犯カメラ | 200の顔またはオブジェクトを同時に処理します。リアルタイムモニタリングに最適です。 |
| ドローン | 自律機能を強化し、さまざまなaiタスクをサポートします。 |
| スマート自律小売 | 小売業におけるai主導のソリューションを強化し、顧客体験と効率を向上させます。 |
| 建設現場モニタリング | 建設会社が現場での活動を追跡するのに役立ちます。 |
| 電力線モニタリング | 公益事業者が電力線を効率的に監視できるようにします。 |
Ascend 310は、高速のai推論が必要ですが、スペースやパワーが限られている場所に展開できます。スマートカメラ、ドローン、小売システムによく合います。
アセンド910C
Ascend 910Cは、その高い計算能力とエネルギー効率で際立っています。あなたは立ち上がるFP16パフォーマンスの320 TFLOPSを使用します。このチップは約310ワットを使用します。これは、多くの競合するGPUよりも低くなっています。それは深い学习および大きいaiモデルのためによく働きます。
| メトリック | アセンド910C | NVIDIA NVL72 B200 |
|---|---|---|
| 電力消費量 (GPUあたり) | NVIDIA NVL72の70%-80% | 100% |
| スーパーノード全体のパフォーマンス (FLOPS) | NVL72より高い70% | 100% |
| FLOPあたりのパワー消費量 | 2.3倍高い | 1.0 |
| TB/sメモリ帯域幅あたりの電力消費量 | 1.8倍高い | 1.0 |
| HBMメモリ容量のTBあたりの電力消費量 | 1.1倍高い | 1.0 |
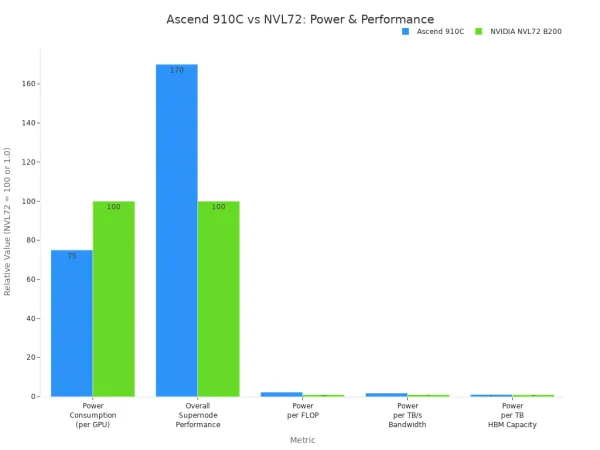
Ascend 910Cを使用して、aiワークロードを要求できます。強力なパフォーマンスと低エネルギーコストが必要なエッジサーバーまたはデータセンターに最適です。このモデルは、大型のaiモデルをリアルタイムでトレーニングして実行するのに理想的です。
注: Ascend 910Cは、NVIDIA A100やH100などのトップGPUと競合します。あなたは高性能を得て、エネルギーを節約します。
アトラス200
Atlas 200はコンパクトなaiアクセラレータモジュールです。それは約ですクレジットカードの半分のサイズを使用します。カメラ、ロボット、ドローンなどの端末で使用できます。このモジュールは、16チャンネルのリアルタイムHDビデオ分析をサポートしています。あなたは小さなパッケージで強いai処理を得ます。
- スマート監視用のカメラにAtlas 200を配置できます。
- リアルタイムの意思決定のためのロボットでうまく機能します。
- ドローンは、強力なナビゲーションと監視にAtlas 200を使用します。
Atlas 200は厳しい環境を処理します。 -20 °Cから55 °Cの温度で動作し、衝撃や振動を処理できます。これにより、屋外またはモバイルaiアプリケーションに適しています。
| 環境要因 | 仕様 |
|---|---|
| 保管温度 | -30〜60 ℃ |
| 操作温度 | -20〜55 ℃ 周囲 |
| 湿度 | 操作: 20% ~ 80% 、相対、非凝縮 |
| テスト | 標準 | パラメーター |
|---|---|---|
| ショック | DIN EN 60068-2-27 | 各軸 (x/y/z) 、20g、11ms、/- 10ショック |
| バンプ | DIN EN 60068-2-27 | 各軸 (x/y/z) 、20g、11ms、/- 100バンプ |
| 振動 (ランダム) | DIN EN 60068-2-64 | 各軸 (x/y/z) 、4.9g rms、15-500Hz、0.05g 2/Hz加速度、軸あたり30分 |
| 振動 (正弦波) | DIN EN 60068-2-6 | 各軸 (x/y/z) 、10-58Hz: 1.5mm、58-500Hz: 10g、1 oct/min、軸あたり1時間52 min |
ヒント: Atlas 200は、特に過酷な環境やモバイル環境で、エッジのaiに最適です。
アトラス500プロ
Atlas 500 Proは、セットトップボックスのサイズで強力なエッジaiソリューションを提供します。リアルタイムのビデオ分析、スマートな輸送、ヘルスケアに使用できます。このデバイスは、最大16テラフロップ (INT8) または8テラフロップ (FP16) の計算能力をサポートします。25〜40ワットを使用し、エネルギー効率が高くなります。
強力なaiパフォーマンスが必要な場所にAtlas 500 Proをデプロイできますが、大規模なサーバー用のスペースがありません。スマートシティのプロジェクト、病院、交通機関のハブによく合います。信頼できるai推論と既存のシステムとの簡単な統合が得られます。
アトラス500プロの主な強み:
- エッジアプリケーションに高いaiパフォーマンスを提供します。
- ビデオおよびセンサーデータのリアルタイム分析をサポートします。
- スペースとパワーが限られている環境で動作します。
コールアウト: Atlas 500 Proは、かさばるハードウェアを必要とせずに、高度なaiをエッジにもたらすのに役立ちます。
これらのモデルを比較すると、それぞれが異なるニーズに適合していることがわかります。Ascend 310とAtlas 200は、小型、モバイル、または屋外のデバイスで最適に機能します。Ascend 910CおよびAtlas 500 Proは、より大きなエッジ展開のためのより多くのパワーを提供します。最良の結果を得るには、aiアプリケーションを適切なモデルに一致させる必要があります。
最適化
モデル圧縮
モデル圧縮手法を使用することで、aiモデルをより高速に実行し、使用するメモリを少なくすることができます。これらの方法は、リソースが限られているエッジにaiをデプロイするのに役立ちます。2つの一般的なテクニックは次のとおりです。
- 量子化: この方法は、モデルの重みの精度を低下させる。あなたはより小さなモデルとより速い推論を得る。
- 知識蒸留: 大きなモデルから学ぶために、小さなモデルをトレーニングします。小さいモデルは良好なパフォーマンスを維持しますが、必要なリソースは少なくなります。
知識蒸留により、aiモデルを縮小できます。あなたは知識を大きな教師モデルから小さな学生モデルに移します。このプロセスは、メモリを節約し、エッジデバイスでの推論を高速化するのに役立ちます。
小さなデバイスでaiアプリケーションをうまく機能させたい場合は、これらのテクニックを試してください。
パワーマネジメント
エッジでaiを実行するときには、パワーを慎重に管理する必要があります。カメラのようなデバイスとセンサー多くの場合、バッテリーの寿命は限られています。低アクティビティ期間中は、省電力モードを使用してAIタスクをスケジュールできます。一部のAscend AIアクセラレータは、動的電圧と周波数のスケーリングをサポートしています。この機能により、ワークロードに基づいて電力使用量を調整できます。過熱を防ぐために、温度とエネルギーの使用を監視することもできます。優れた電源管理により、aiシステムをより長く、より確実に稼働させることができます。
ヒント: スマートパワーマネジメントは、aiデバイスが長持ちし、厳しい環境でよりよく機能することを意味します。
ソフトウェアサポート
Ascend AI Acceleratorsにaiを展開するのに役立つ多くのソフトウェアフレームワークとツールがあります。これらのツールを使用すると、モデルの構築、テスト、および最適化が容易になります。以下の表は、いくつかの一般的なオプションを示しています:
| フレームワーク/ツール | 説明 |
|---|---|
| PyTorch | ラピッドプロトタイピングと実験に理想的な動的計算グラフフレームワーク。 |
| TensorFlow | さまざまなタスクに広く使用されている、複数の言語をサポートする多用途の機械学習システム。 |
| マインド胞子 | Ascend AIプロセッサ用に最適化されたHuaweiのオープンソースフレームワークは、共同設計を通じてパフォーマンスを向上させます。 |
| Apache MXNet | 複数のプログラミング言語をサポートするAWSのディープラーニングフレームワーク。 |
| カフェ | 新しいデータ形式とネットワークレイヤーを簡単に拡張するために開発されたモジュラーフレームワーク。 |
| ディープトーチ推論 | PyTorchモデル用の推論アクセラレータであり、高度な技術を通じてパフォーマンスを向上させます。 |
| MindStudio 2.0 | 開発者のプロセスを簡素化する、エンドツーエンドのAI開発のための包括的なツールです。 |
プロジェクトに最適なフレームワークを選択できます。MindSporeはAscendプロセッサでうまく機能し、パフォーマンスを向上させます。PyTorchとTensorFlowは、柔軟性とコミュニティサポートが必要な場合に適しています。MindStudio 2.0は、ai開発を最初から最後まで管理するのに役立ちます。
決定チェックリスト
要件の一致
アプリケーション要件がAscend AI Acceleratorの機能に適合していることを確認する必要があります。プロジェクトに必要なものをリストすることから始めます。速度、パワー、サイズ、コスト、およびソフトウェアのサポートについて考えます。以下のチェックリストを使用して、決定を導きます。
- パフォーマンス: アプリケーションに高速な画像またはビデオ分析が必要ですか? テラフロップとメモリ帯域幅を確認します。
- パワー効率: デバイスはバッテリーで動作しますか、それとも電力が限られている場所で動作しますか? 低ワット数モデルを探してください。
- フォームファクター: プロジェクトには小さなモジュールまたは大きなエッジステーションが必要ですか? サイズをデプロイスペースに合わせます。
- コスト: あなたは余裕がありますかハードウェアとメンテナンス?エネルギーとサポートを含む総コストを計算します。
- 互換性: ソフトウェアはTensorFlow、PyTorch、MindSporeなどのAscendフレームワークで動作しますか? モデルがスムーズに実行されることを確認します。
ヒント: 上位3つの要件を書き留めます。それらを使用して、各Ascendモデルを比較します。これは、プロジェクトにとって最も重要なことに集中するのに役立ちます。
| 要件 | 例の必要性 | 一致するように機能をAscend Feature to Match |
|---|---|---|
| スピード | リアルタイムビデオ | 高TFLOPS、高速メモリ |
| パワー | バッテリー操作 | 低ワット数、効率的なチップ |
| サイズ | ドローンまたはカメラ | コンパクトモジュール |
| コスト | 予算制限 | 低TCO、省エネ |
| ソフトウェア | PyTorchのサポート | フレームワークの互換性 |
選択手順
次の手順に従って、Ascend AIアクセラレータを選択してデプロイします。
- アプリケーションの目標を定義するを使用します。AIシステムに何をしたいかを書き留めます。
- 技術的なニーズを一覧表示するを使用します。速度、パワー、サイズ、コスト、ソフトウェアが含まれます。
- Ascendモデルを比較するを使用します。チェックリストを使用して、各モデルの機能を一致させます。
- AIモデルをテストする選択したハードウェアに速度と精度の目標を満たしているかどうかを確認します。
- パワーとコストを確認するを使用します。デバイスが予算とエネルギー計画に合っていることを確認してください。
- ソフトウェアの互換性を確認するを使用します。フレームワークとツールがアクセラレータで動作することを確認します。
- デプロイの計画を使用します。デバイスをインストールする場所と方法を決定します。
- パフォーマンスのモニターを使用します。結果を追跡し、最高の効率のために設定を調整します。
注: 新しいプロジェクトごとにこれらの手順を繰り返すことができます。このプロセスは、毎回正しいアクセラレータを選択するのに役立ちます。
アプリケーションのニーズを適切なAscend AI Acceleratorと一致させると、エッジ推論が改善されます。より高速なトレーニング、よりシンプルなモデル、より良い検出率が見られます。
| 特徴 | 説明 |
|---|---|
| トレーニング時間 | 75% 削減 |
| 推論速度 | 32.99% 増加 |
| 検出mAP | 97.1% |
このチェックリストを使用する必要があります:
- スピードとパワーのニーズを一覧表示します。
- あなたの予算に合ったモデルを選んでください。
- ソフトウェアのサポートを確認します。
- 将来のアップグレードを計画します。
エッジAIが進化するにつれて、最新の状態を維持します。AIコプロセッサ、5G、IoTなどの新しいトレンドは、あなたができることを変え続けています。
よくある質問
Ascend AIアクセラレータとは何ですか?
Ascend AI Acceleratorを使用してAIタスクを高速化します。デバイスがデータをすばやく処理するのに役立ちます。画像分析やビデオモニタリングなどのパフォーマンスが向上します。
どのAscendモデルがプロジェクトに適合するかを知るにはどうすればよいですか?
速度、パワー、サイズ、コストのニーズをリストします。これらのニーズを各モデルの機能と比較します。要件に最適なモデルを選択します。
ヒント: 選択する前に、上位3つのニーズを書き留めてください。
AscendデバイスでPyTorchまたはTensorFlowを実行できますか?
ほとんどのAscendデバイスでPyTorchとTensorFlowを実行できます。Huaweiはアダプターとオープンソースツールを提供しています。あなたは互換性の確認AIモデルを展開する前に。
| フレームワーク | アセンドでサポートされていますか? |
|---|---|
| PyTorch | ✅ |
| TensorFlow | ✅ |
| マインド胞子 | ✅ |
Ascend AIアクセラレータは過酷な環境で機能しますか?
あなたはいくつかを使うことができますAscendモデル、アトラス200のように、厳しい状況で。これらのデバイスは、熱、寒さ、衝撃、および振動を処理します。各モデルの仕様をチェックして、環境に合っていることを確認します。
- アトラス200:-20 °Cから55 °Cまでの作品
- ショックやバンプを処理する





