

HiSiliconのレイテンシーが重要な理由をリアルタイムAI処理
HiSilicon AI SoCの場合、低レイテンシが最も重要なパフォーマンスメトリックです。このハードウェアは低レイテンシのパフォーマンスに重点を置いていますe

HiSilicon AI SoCの場合、低レイテンシが最も重要なパフォーマンスメトリックです。このハードウェアは、低遅延パフォーマンスに重点を置いて、リアルタイムのデータ処理を可能にします。AI市場の予測までの成長2034年までに1,430億ドルこのハードウェア性能に対する需要を強調しています。レイテンシが重要なシステムでは、100ミリ秒を超える遅延は安全性能を低下させますを参照してください。HiSiliconの特殊なハードウェアアーキテクチャは、このエンドツーエンドの遅延パフォーマンスを優先します。このハードウェア設計により、優れた実世界のAIパフォーマンスが保証されます。Raw TOPSは真のハードウェアパフォーマンスを反映できませんを参照してください。ハードウェア自体がAIハードウェアパフォーマンスの中核であるため、このハードウェアはレイテンシパフォーマンスに重点を置いているため、AIハードウェアパフォーマンスの鍵となります。
重要なポイント
- 低レイテンシは、HiSiliconのAIチップにとって非常に重要です。それは意味しますチップリアルタイムタスクの鍵となる意思決定を迅速に行います。
- Da Vinci NPUと呼ばれるHiSiliconの特別なデザインは、AIモデルの高速動作に役立ちます。ユニークな3Dキューブを使用して数学をすばやく行います。
- の特別な部品チップ、画像信号プロセッサのように、主要なAI部分を助けます。彼らは特定の仕事をすることによってシステム全体をより速くします。
- 高速AI処理は、自動運転車、スマートシティ、スマートデバイスに役立ちます。それは彼らをより安全にし、実生活でより良く働く。
エッジAIでLATENCYが重要な理由

エッジAIアプリケーションでは、ミリ秒ごとにカウントされます。システムはデータストリームをリアルタイムで処理する必要があります。データストリームが遅れると、イベントの失敗や誤ったアクションが発生する可能性があります。これがレイテンシが重要な理由です。制御アルゴリズムは、安定性と安全性を維持するために、即時の推論決定に依存します。遅延は、システム全体の性能を損なう可能性がある。真のハードウェアパフォーマンスは、処理能力だけではありません。それは、最終的な実用的な出力の速度に関するものです。
AI処理の遅れを定義する
専門家は、AIモデルが入力を受信して予測を返すのにかかる時間としてAI推論レイテンシを正式に定義します。この測定は、典型的にはミリ秒 (ms) で表される。ただし、エンドツーエンドのレイテンシは、システムパフォーマンスのより完全な画像を提供します。データキャプチャから最終アクションまでの全道のりをカバーします。
この総レイテンシには、いくつかの異なるステージが含まれます:
- データの取り込みと前処理: ハードウェアはまず入力データを準備します。このステップでは、AIモデルに到達する前にデータをフォーマットして検証します。
- モデル推論: これがコア計算時間です。ハードウェアはAIモデルを実行して、入力データに基づいて予測を生成します。ここでの推論性能は重要です。
- ポスト処理と出力: ハードウェアはモデルの出力をフォーマットします。これは、ロボットアームコントローラやディスプレイなどの次のシステムコンポーネントの結果を準備します。
注:インタラクティブAIの場合、他のメトリックもハードウェアのパフォーマンスを強調します。初めてトークン (TTFT) までの時間ユーザーが最初の応答をどれだけ早く取得するかを測定します。これは、スムーズなユーザーエクスペリエンスに不可欠です。
一般的な目的のCPUSの制限
汎用CPUは、現代のAIの要求に応じて構築されていません。CPUは、通常4〜64の少数の強力なコアを使用します。このアーキテクチャは、複雑でシーケンシャルなタスクに優れています。ただし、AIモデルには大規模な並列計算が必要であり、一度に何千もの単純な操作を実行します。この不一致は、重大なパフォーマンスのボトルネックを生じる。CPUの設計は、並列ワークロードの推論パフォーマンスを制限します。
強力なGPUを備えたシステムでも、CPUは、特に遅延に敏感なアプリケーションで全体的なパフォーマンスを制約する可能性があります。CPUは、アクセラレータにデータをすばやくフィードするのに苦労しているため、システムの推論パフォーマンスが低下します。これが理由です特殊なハードウェア最適なAIパフォーマンスには必要です。
ベンチマークは、CPUとの間のパフォーマンスギャップを明確に示しています。神経処理ユニット(NPU)。YOLOv3のような一般的なAIモデルの場合、NPUははるかに優れた推論パフォーマンスを提供します。
| システムタイプ | 相対レイテンシの削減 |
|---|---|
| CPU専用システム | ベースライン |
| NPU-Poweredシステム | 〜1.6x高速 |
このデータは、専用ハードウェアがAIモデルの実行に必要な時間を大幅に短縮することを示しています。NPUのアーキテクチャ上の利点は、遅延の短縮と優れた推論パフォーマンスに直接つながります。以下のグラフは、さまざまな特殊なハードウェアプラットフォームが一般的なAIモデルに対してさまざまな遅延を実現する方法をさらに示しています。
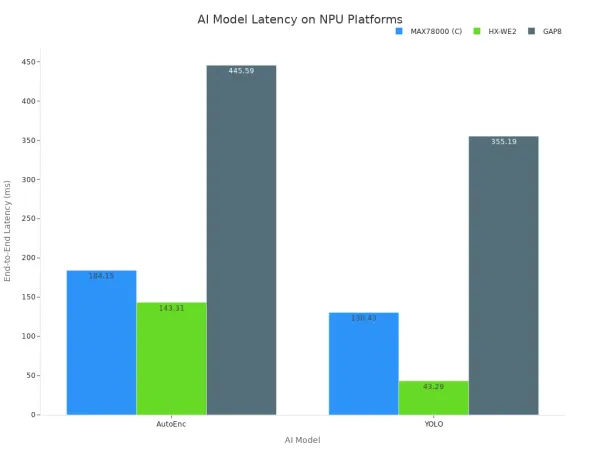
最終的に、リアルタイムAIタスクをCPUに依存すると、システムの応答性が低下します。ハードウェアは単に仕事のために設計されていません。重要な低遅延を実現するには、AIモデル専用のハードウェアが必要であり、一流の推論パフォーマンスと信頼性を確保します。
低LATENCYのためのHISILICONのアーキテクチャ

HiSiliconは、全体的なハードウェアアーキテクチャを通じて、業界をリードする低遅延パフォーマンスを実現しています。この設計は、単一の強力なプロセッサを超えています。特殊なコンピューティングコア、高速を統合しますメモリシステム、および専用ハードウェアアクセラレータ。この組み合わせにより、データは最大限の効率で移動し、処理されます。これは、リアルタイムAIアプリケーションに不可欠です。システム全体のパフォーマンスは、このタイトな統合に依存します。
DA VINCI NPUコア
Da Vinci Neural Processing Unit (NPU) は、HiSiliconのAIハードウェアの中心です。このNPUは、パワーの数学的操作のために特別に設計された強力なAIアクセラレータですモダンなAIモデルを参照してください。そのアーキテクチャは均一ではありません。さまざまなタイプの計算ユニットを組み合わせてパフォーマンスを最適化します。この異質なデザイン優れた推論性能の主な理由です。
コアには、一緒に働く3つの主要コンポーネントが含まれています。
- スカラー単位これらは、AIモデルの一般的なロジックと制御フローを処理します。
- ベクトル単位: これらは、多くの単純な操作を一度に実行するのに優れており、AIモデルの特定のレイヤーに対する一般的なニーズです。
- 3Dキューブユニット: これはAIアクセラレーションにとって最も重要なコンポーネントです。これらのユニットは、信じられないほどの速度で行列乗算を実行するように構築されています。
この構造により、Da Vinciコアは複雑なAIモデルを最小限の遅延で処理できます。立方体単位は行列数学の重い持ち上げを処理し、ベクトル単位とスカラー単位は周囲のタスクを管理します。AIアクセラレータ内のこの分業により、ハードウェアの一部がボトルネックになることはありません。その結果、優れた推論パフォーマンスと、要求の厳しいAIワークロードに対する低遅延が実現します。これらのAIアクセラレータは、システム全体のパフォーマンスの基本です。
オンチップ記憶とインターネット
高速NPUは高速データを必要とする。AIアクセラレータがデータを待つ必要がある場合、そのパフォーマンスの利点は失われます。HiSiliconのハードウェア設計は、洗練されたオンチップメモリ階層と高速相互接続でこの課題に対処します。これらのコンポーネントはデータスーパーハイウェイを作成し、チップ周辺の情報の移動に関連する遅延を最小限に抑えます。この効率的なデータフローは、ハードウェアの推論性能にとって重要である。
HiSilicon SoCは、高度な相互接続を使用してNPU、CPU、およびメモリをリンクします。これにより、すべてのコンポーネントが最小限の遅延で通信できるようになります。メモリ技術の選択は、システム性能においても重要な役割を果たす。
| チップモデル | 相互接続 | メモリ技術 |
|---|---|---|
| キリン960 | ARM CCI-550 | LPDDR4-1600 (64ビットデュアルチャネル) |
| キリン970 | ARM CCI-550 | LPDDR4 |
メインメモリを超えて、システムはオンチップメモリ (キャッシュ) のいくつかの層を使用します。Da Vinci NPU自体は、それ自体のローカルメモリを含む。これにより、AIアクセラレータはAIモデルで頻繁に使用されるデータを計算ユニットのすぐ隣に保持できるため、データアクセスの待ち時間が大幅に短縮されます。このアーキテクチャはまた、電力効率を改善する。多くの場合、ネットワークオンチップ (NoC) によって管理される効率的なオンチップデータフローは、柔軟なパケットでデータを送信することにより、消費電力を削減します。このアプローチは、物理的なワイヤ数を低下させ、性能を改善する。他の技術はこの効率をさらに高めます:
- 細粒ゲーティング: この方法では、クロックゲーティングを使用してハードウェアユニット間のデータフローを調整します。
- バッファリング: 明示的バッファ (FIFOs) は、AIアクセラレータが必要なときに正確にデータを利用できるようにし、失速や無駄なエネルギーを防ぎます。
専用ハードウェア加速
NPUはスタープレーヤーですが、チームの唯一のハードウェアアクセラレータではありません。HiSilicon SoCは、特定のタスクを処理する専用のハードウェアアクセラレータのスイートを統合しています。これらのアクセラレータは、CPUとNPUから作業をオフロードし、AIパイプライン全体のエンドツーエンドの遅延を削減します。このアプローチは、リアルタイムビデオ分析などの複雑なタスクに不可欠であり、効果的なオンデバイス推論を可能にします。
コンピュータビジョンアプリケーションでは、画像信号プロセッサ (ISP)は重要なハードウェアアクセラレータです。ISPはNPUと直接連携して、より良い推論パフォーマンスを提供します。
- ISPは、ハイダイナミックレンジ (HDR) フュージョンや高度なノイズリダクションなどの初期画像処理タスクを処理します。
- NPUで実行されているAIモデル専用のビデオデータを準備して最適化します。
- 専用のハードウェアアクセラレータによるこの前処理は、NPUがクリーンですぐに分析できるデータを受信することを意味し、最終的なAI結果を高速化します。
同様に、ハードウェアベースのビデオエンコーダとデコーダは、高解像度ビデオストリームを分析するために不可欠なAIアクセラレータです。これらのアクセラレータは、ビデオ処理パイプライン全体を単一のチップで管理します。
- CPUに負担をかけることなく、着信ビデオストリームをデコードします。
- これらにより、NPUはビデオをローカルで分析できます。
- 重要なイベントデータのみを送信するため、ネットワーク帯域幅とストレージコストが大幅に削減されます。
専用のハードウェアアクセラレータのこのチームは、データキャプチャから最終出力まで、AIタスクのすべてのステージが速度に合わせて最適化されることを保証します。ハードウェア設計に対するこの包括的なアプローチは、HiSiliconにリアルタイムAIの低遅延パフォーマンスの優位性を与えるものです。これらのアクセラレータ間の相乗効果は、単一のプロセッサでは一致できないレベルのパフォーマンスを提供します。
現実世界の低最近のアプリケーション
低遅延ハードウェアは、新世代のインテリジェントシステムのロックを解除します。これらのシステムの性能は、即座のデータ処理に依存する。HiSiliconのハードウェアアーキテクチャは、重要な実世界のAIアプリケーションに必要な速度を提供します。AIモデルの優れたパフォーマンスにより、ミリ秒が重要な場所で即座に意思決定が可能になります。
屋外システム
自律システムでは、低レイテンシは安全性と精度のための交渉不可能な要件です。ハードウェアは処理する必要がありますセンサーデータとAIモデルを最小限の遅延で実行し、信頼性の高いパフォーマンスを確保します。
- 自律型車両: 自動運転車の場合、歩行者を検出してブレーキをかけるには、50〜100ミリ秒のエンドツーエンドのレイテンシを参照してください。これを超える遅延は安全性を損なう。車両のハードウェアは、この性能を一貫して提供しなければならない。
- 産業用ロボット工学: Onアセンブリライン、ロボットは正確なタスクを実行するために迅速なフィードバックが必要です。Sub-100ms実行サイクルAIモデルのためによりよい品质管理および高められた労働者の安全。この低遅延ハードウェアパフォーマンスは、製造スループットを直接向上させますを参照してください。
スマートインフラ
スマートシティと工場は、カメラのAI分析を使用して効率とセキュリティを向上させます。これには、ビデオストリームをリアルタイムで処理できる強力なエッジハードウェアが必要です。これらのAIモデルのパフォーマンスは、成功の鍵です。
リアルタイム脅威検出:スマートシティでは、AIカメラが公共スペースを監視します。ハードウェアはビデオフィードを分析します交通違反、放棄されたオブジェクト、またはその他の潜在的な脅威を特定し、即座に対応できるようにします。このAIパフォーマンスは、法執行を支援し、緊急サービスを最適化しますを参照してください。
スマートな工場では、AIビジョンシステムは、即座の品質管理を提供します。ハードウェアは、アセンブリラインで製品を分析する検査モデルを実行します, 傷や不整合などの欠陥を特定するを参照してください。この即時のフィードバックは、生産を遅くすることなく製品の品質を向上させます。ここでは、AIモデルのパフォーマンスが重要です。
スマートデバイスとメディア
低遅延AI処理により、家電製品やヘルスケア機器のユーザーエクスペリエンスが向上します。ハードウェアは、デバイス上で直接実行される高度な機能を可能にします。
スマートテレビの使用リアルタイム8KビデオのアップスケーリングのためのAIモデル。ハードウェアのAIプロセッサは、コンテンツをフレームごとに分析して詳細を強化し、ノイズを低減します、優れた画像を提供します。この高レベルのパフォーマンスは即座に起こります。遠隔医療とウェアラブルの場合、デバイス上のハードウェアバイオメトリックデータを分析します。緊急イベント検出モデルでは、50ミリ秒未満のレイテンシが必要です。ユーザーまたは医療関係者に警告します。この迅速なAIパフォーマンスは、命を救うことができます。
リアルタイムエッジAIの場合、エンドツーエンドの遅延が重要です。生の計算スループットだけでは、真のハードウェアパフォーマンスは定義されませんを参照してください。Da Vinci NPUと専用ハードウェアアクセラレータを備えたHiSiliconのハードウェアアーキテクチャは、この重要な低遅延パフォーマンスを提供します。これらのハードウェアアクセラレータのパフォーマンスが重要です。ハードウェアアクセラレータは優れた性能を提供します。
開発者向けのメモ:レイテンシのハードウェアをベンチマークする必要があります。これにより、実世界のハードウェア性能と信頼性が保証されます。レイテンシは、このハードウェア性能にとって重要である。ハードウェアアクセラレータおよびハードウェアは、この性能を提供する。ハードウェアアクセラレータのパフォーマンスは非常に重要です。ハードウェア性能は、これらのハードウェアアクセラレータに依存する。
よくある質問
エッジAIのTOPSよりもレイテンシが重要なのはなぜですか?
TOPSは生の処理能力を測定します。レイテンシーは、決定の合計時間を測定します。自動運転などのリアルタイムアプリケーションの場合、高速な決定は、高い計算スループットよりも安全性とパフォーマンスにとってより重要です。
低レイテンシにより、システムは新しい情報に即座に反応できます。
ダヴィンチNPUとは何ですか?
Da Vinci NPUは、HiSiliconの特殊なAIアクセラレータです。マトリックス数学に独自の3D Cubeアーキテクチャを使用します。この設計により、AIモデルの計算が大幅に高速化されます。推論レイテンシを直接削減し、リアルタイムタスクのシステム全体のパフォーマンスを向上させます。
ハードウェアアクセラレータはAIパフォーマンスをどのように改善しますか?
イメージシグナルプロセッサ (ISP) のようなハードウェアアクセラレータは、特定のジョブを処理します。メインプロセッサからタスクをオフロードします。この並列処理はボトルネックを減らす。AIパイプライン全体の実行速度が速くなり、エンドツーエンドの遅延が短縮され、効率的なオンデバイス推論が可能になります。
超低レイテンシが必要なアプリケーション
即時のアクションが必要なアプリケーションには、低レイテンシが必要です。これらのシステムは、迅速なリアルタイムの意思決定に依存する。主な例は次のとおりです。
- 自律システム (車両、ロボット)🤖
- スマートインフラストラクチャ (脅威検出)🏙️
- 高度なメディア (8Kアップスケーリング)📺
- 遠隔医療 (緊急警報)❤️🩹





