

Procesamiento de IA en tiempo real Por qué la latencia es clave para HiSilicon
Para HiSilicon AI SoCs, la baja latencia es la métrica de rendimiento más crítica. Este hardware se centra en el rendimiento de baja latencia e

Para HiSilicon AI SoCs, la baja latencia es la métrica de rendimiento más crítica. Este enfoque de hardware en el rendimiento de baja latencia permite el procesamiento de datos en tiempo real. El crecimiento del mercado de AI a un nivel proyectado143 mil millones de dólares para 2034Destaca la demanda de este rendimiento de hardware. En sistemas donde la latencia importa,Un retraso de más de 100 milisegundos degrada el rendimiento de seguridad. La arquitectura de hardware especializada de HiSilicon prioriza este rendimiento de latencia de extremo a extremo. Este diseño de hardware garantiza un rendimiento superior de la IA en el mundo real.RAW TOPS no refleja el verdadero rendimiento del hardware. Este enfoque de hardware en el rendimiento de latencia es clave para el rendimiento del hardware de AI, ya que el hardware en sí es el núcleo del rendimiento del hardware de AI.
Puntos clave
- La baja latencia es muy importante para los chips AI de HiSilicon. Significa elChipToma decisiones rápidamente, lo cual es clave para las tareas en tiempo real.
- El diseño especial de HiSilicon, llamado Da Vinci NPU, ayuda a que los modelos de IA funcionen rápidamente. Utiliza un cubo 3D único para hacer matemáticas rápidamente.
- Partes especiales en elChip, Como el procesador de señal de imagen, ayuda a la parte principal de AI. Hacen que todo el sistema sea más rápido al realizar trabajos específicos.
- El procesamiento rápido de IA ayuda a los automóviles autónomos, las ciudades inteligentes y los dispositivos inteligentes. Los hace más seguros y funcionan mejor en la vida real.
POR QUÉ LA LATENCIA IMPORTA EN EDGE AI

En aplicaciones Edge AI, cada milisegundo cuenta. El sistema debe procesar flujos de datos en tiempo real, donde quedarse atrás puede llevar a eventos perdidos o acciones incorrectas. Es por eso que la latencia importa. Los algoritmos de control dependen de decisiones de inferencia inmediatas para mantener la estabilidad y la seguridad. Un retraso puede comprometer el rendimiento de todo el sistema.El verdadero rendimiento del hardware no se trata solo de la potencia de procesamiento; se trata de la velocidad de la salida final y procesable.
DEFINICIÓN DE LA LATENCIA DE PROCESAMIENTO AI
Los profesionales definen formalmente la latencia de inferencia de la IA como el tiempo que tarda un modelo de IA en recibir una entrada y devolver una predicción. Esta medida se expresa típicamente en milisegundos (ms).Sin embargo, la latencia de extremo a extremo proporciona una imagen más completa del rendimiento del sistema. Cubre todo el viaje desde la captura de datos hasta la acción final.
Esta latencia total incluye varias etapas distintas:
- Ingestión de datos y preprocesamientoEl hardware prepara primero los datos de entrada. Este paso implica formatear y validar los datos antes de que lleguen a los modelos de IA.
- Inferencia del modelo: Este es el tiempo de cálculo del núcleo. El hardware ejecuta los modelos de AI para generar una predicción basada en los datos de entrada. El rendimiento de la inferencia aquí es crítico.
- Post-procesamiento y salida: El hardware da formato a la salida del modelo. Prepara el resultado para el siguiente componente del sistema, como un controlador de brazo robótico o una pantalla.
Nota:Para la IA interactiva, otras métricas también resaltan el rendimiento del hardware.Tiempo hasta el primer token (TTFT)Mide la rapidez con la que un usuario obtiene la primera parte de una respuesta, lo cual es vital para una experiencia de usuario fluida.
LIMITACIONES DEL CPUS DE PROPÓSITO GENERAL
Las CPU de propósito general no están construidas para las demandas de la IA moderna.Las CPU utilizan un pequeño número de núcleos potentes, generalmente entre 4 y 64. Esta arquitectura sobresale en tareas complejas y secuenciales. Sin embargo, los modelos de IA requieren cálculos paralelos masivos, ejecutando miles de operaciones simples a la vez. Este desajuste crea un cuello de botella de rendimiento significativo.El diseño de la CPU limita su rendimiento de inferencia para cargas de trabajo paralelas.
Incluso en sistemas con una GPU potente, la CPU puede limitar el rendimiento general, especialmente en aplicaciones sensibles a la latencia.La CPU lucha para alimentar datos al acelerador lo suficientemente rápido, lo que perjudica el rendimiento de inferencia del sistema. Esto es por quéHardware especializadoEs necesario para un rendimiento óptimo de AI.
Los puntos de referencia muestran claramente la brecha de rendimiento entre las CPU y el hardware especializado comoUnidades de Procesamiento Neural(NPUs). Para modelos de IA comunes como YOLOv3, las NPU ofrecen un rendimiento de inferencia mucho mejor.
| Tipo de sistema | Reducción de la latencia relativa |
|---|---|
| Sistema de sólo CPU | Línea base |
| Sistema alimentado por NPU | ~ 1.6x más rápido |
Estos datos muestran que el hardware dedicado reduce significativamente el tiempo necesario para ejecutar modelos de IA. La ventaja arquitectónica de las NPU se traduce directamente en una menor latencia y un rendimiento de inferencia superior. El siguiente gráfico ilustra cómo las diferentes plataformas de hardware especializadas logran una latencia variable para los modelos populares de IA.
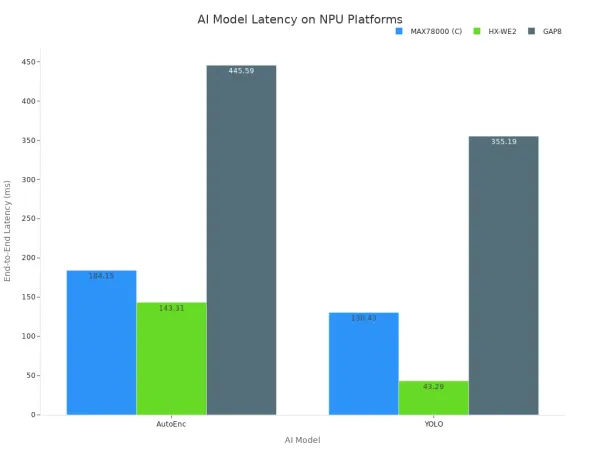
En última instancia, confiar en las CPU para las tareas de IA en tiempo real compromete la capacidad de respuesta del sistema. El hardware simplemente no está diseñado para el trabajo. Lograr la baja latencia que importa requiere hardware diseñado especialmente para los modelos de IA, lo que garantiza el rendimiento y la fiabilidad de la inferencia de primer nivel.
ARQUITECTURA DE HISILICONA PARA BAJA LATENCIA

HiSilicon logra su rendimiento de baja latencia líder en la industria a través de una arquitectura de hardware holística. Este diseño va más allá de un único y potente procesador. Integra núcleos informáticos especializados, una alta velocidadMemoriaY aceleradores de hardware dedicados. Esta combinación garantiza que los datos se mueven y se procesan con la máxima eficiencia, lo cual es esencial para las aplicaciones de IA en tiempo real. El rendimiento general del sistema depende de esta estrecha integración.
EL NÚCLEO DE DA VINCI NPU
La Unidad de Procesamiento Neural (NPU) Da Vinci es el corazón del hardware de IA de HiSilicon. Este NPU es un potente acelerador de AI diseñado específicamente para las operaciones matemáticas que el poderModelos modernos de AI. Su arquitectura no es uniforme; combina diferentes tipos de unidades de cálculo para optimizar el rendimiento. EstoDiseño heterogéneoEs una razón clave para su excelente rendimiento de inferencia.
El núcleo contiene tres componentes principales que trabajan juntos:
- Unidades escalaresEstos manejan lógica general y flujo de control para los modelos de IA.
- Unidades vectorialesEstos son excelentes para ejecutar muchas operaciones simples a la vez, una necesidad común para ciertas capas en los modelos de IA.
- Unidades del cubo 3DEste es el componente más crítico para la aceleración de la IA. Estas unidades están construidas para realizar la multiplicación de matrices a velocidades increíbles.
Esta estructura permite que el núcleo Da Vinci procese modelos de IA complejos con un retraso mínimo. Las unidades de cubo manejan el trabajo pesado de las matemáticas de la matriz, mientras que las unidades vectoriales y escalares administran las tareas circundantes. Esta división del trabajo dentro del acelerador de IA garantiza que ninguna parte del hardware cree un cuello de botella. El resultado es un rendimiento de inferencia superior y menor latencia para cargas de trabajo de IA exigentes. Estos aceleradores de IA son fundamentales para el rendimiento general del sistema.
MEMORIA EN CHIP E INTERCONEXIONES
Una NPU rápida necesita datos rápidos. Si el acelerador de IA debe esperar datos, se pierde su ventaja de rendimiento. El diseño de hardware de HiSilicon aborda este desafío con una sofisticada jerarquía de memoria en chip e interconexiones de alta velocidad. Estos componentes crean una superautopista de datos, minimizando la latencia asociada con el movimiento de la información alrededor del chip. Este flujo de datos eficiente es crítico para el rendimiento de inferencia del hardware.
Los SoC HiSilicon utilizan interconexiones avanzadas para vincular la NPU, la CPU y la memoria. Esto garantiza que todos los componentes puedan comunicarse con un retraso mínimo. La elección de la tecnología de memoria también juega un papel vital en el rendimiento del sistema.
| Modelo de chip | Interconexión | Tecnología de la memoria |
|---|---|---|
| Kirin 960 | BRAZO CCI-550 | LPDDR4-1600 (doble canal de 64 bits) |
| Kirin 970 | BRAZO CCI-550 | LPDDR4 |
Más allá de la memoria principal, el sistema utiliza varias capas de memoria en el chip (cachés). La propia NPU Da Vinci contiene su propia memoria local. Esto permite que el acelerador AI mantenga los datos utilizados con frecuencia para los modelos AI justo al lado de las unidades de cálculo, reduciendo drásticamente la latencia de acceso a los datos. Esta arquitectura también mejora la eficiencia energética.El flujo de datos en chip eficiente, a menudo administrado por una red en chip (NoC), reduce el consumo de energía al enviar datos en paquetes flexibles. Este enfoque reduce el número de cables físicos y mejora el rendimiento.Otras técnicas mejoran aún más esta eficiencia:
- Gating de grano finoEste método utiliza el clock gating para regular el flujo de datos entre las unidades de hardware.
- Buffering (búfer)Los buffers explícitos (FIFO) aseguran que los datos estén disponibles precisamente cuando el acelerador de IA los necesita, evitando bloqueos y desperdicio de energía.
ACELERACIÓN DE HARDWARE DEDICADO
La NPU es el jugador estrella, pero no es el único acelerador de hardware en el equipo. Los SoC de HiSilicon integran un conjunto de aceleradores de hardware dedicados que manejan tareas específicas. Estos aceleradores descargan el trabajo de la CPU y la NPU, reduciendo la latencia de extremo a extremo de toda la tubería de AI. Este enfoque es vital para tareas complejas como el análisis de video en tiempo real y permite una inferencia efectiva en el dispositivo.
En las aplicaciones de visión por computador, elProcesador de señal de imagen (ISP)Es un acelerador de hardware crucial. El ISP trabaja directamente con la NPU para ofrecer un mejor rendimiento de inferencia.
- El ISP maneja tareas iniciales de procesamiento de imágenes como la fusión de alto rango dinámico (HDR) y la reducción avanzada de ruido.
- Prepara y optimiza los datos de video específicamente para los modelos de AI que se ejecutan en la NPU.
- Este preprocesamiento por un acelerador de hardware dedicado significa que la NPU recibe datos limpios y listos para analizar, lo que acelera el resultado final de la IA.
Del mismo modo, los codificadores y decodificadores de video basados en hardware son aceleradores de IA esenciales para analizar flujos de video de alta resolución. Estos aceleradores administran toda la canalización de procesamiento de video en un solo chip.
- Decodifican los flujos de vídeo entrantes sin sobrecargar la CPU.
- Permiten que la NPU analice el video localmente.
- Transmiten solo datos de eventos críticos, lo que reduce drásticamente el ancho de banda de la red y los costos de almacenamiento.
Este equipo de aceleradores de hardware especializados garantiza que cada etapa de una tarea de IA, desde la captura de datos hasta el resultado final, esté optimizada para la velocidad. Este enfoque integral para el diseño de hardware es lo que le da a HiSilicon su ventaja en el rendimiento de baja latencia para la IA en tiempo real. La sinergia entre estos aceleradores ofrece un nivel de rendimiento que un solo procesador no puede igualar.
APLICACIONES DE BAJA LATENCIA EN EL MUNDO REAL
El hardware de baja latencia desbloquea una nueva generación de sistemas inteligentes. El rendimiento de estos sistemas depende del procesamiento inmediato de los datos. La arquitectura de hardware de HiSilicon proporciona la velocidad necesaria para aplicaciones críticas de IA en el mundo real. El rendimiento superior de sus modelos de IA permite la toma de decisiones instantánea donde los milisegundos son importantes.
SISTEMAS AUTÓNOMOS
En los sistemas autónomos, la baja latencia es un requisito no negociable para la seguridad y la precisión. El hardware debe procesarSensorDatos y ejecutar modelos de IA con un retraso mínimo para garantizar un rendimiento fiable.
- Vehículos autónomosPara un coche autónomo, la detección de un peatón y la aplicación de los frenos requiere unLatencia de extremo a extremo de 50 a 100 milisegundos. Cualquier retraso más allá de esto compromete la seguridad. El hardware del vehículo debe ofrecer este rendimiento de manera consistente.
- Robótica Industrial: En unAsambleaLínea, los robots necesitan retroalimentación rápida para realizar tareas precisas.Ciclos de ejecución Sub-100msPara AI modelos permitenUn mejor control de calidad y una mayor seguridad de los trabajadores. Este rendimiento de hardware de baja latencia mejora directamente el rendimiento de fabricación.
INFRAESTRUCTURA INTELIGENTE
Las ciudades y fábricas inteligentes utilizan el análisis de IA en la cámara para mejorar la eficiencia y la seguridad. Esto requiere un potente hardware de borde capaz de procesar flujos de vídeo en tiempo real. El rendimiento de estos modelos de IA es clave para su éxito.
Detección de amenazas en tiempo real:En las ciudades inteligentes, las cámaras de IA monitorean espacios públicos. El hardware analiza alimentaciones de vídeo aIdentificar infracciones de tráfico, objetos abandonados u otras amenazas potenciales, permitiendo una respuesta inmediata. Este rendimiento de AI ayuda a la aplicación de la ley y optimiza los servicios de emergencia.
En las fábricas inteligentes,Los sistemas de la visión del AI proporcionan control de calidad inmediato. El hardware ejecuta modelos de inspección que analizan productos en la línea de montaje,Identificación de defectos como arañazos o desalineaciones. Esta retroalimentación inmediata mejora la calidad del producto sin ralentizar la producción. El rendimiento de los modelos de IA es crítico aquí.
MEDIOS Y DISPOSITIVOS INTELIGENTES
El procesamiento de IA de baja latencia mejora la experiencia del usuario en la electrónica de consumo y los dispositivos sanitarios. El hardware permite funciones sofisticadas que se ejecutan directamente en el dispositivo.
Uso de televisores inteligentesModelos de AI para escalado de video 8K en tiempo real. El procesador AI del hardware analiza el contenido fotograma a fotograma para mejorar los detalles y reducir el ruidoEntregando una imagen superior. Este rendimiento de alto nivel ocurre instantáneamente. Para telemedicina y wearables,Hardware en el dispositivoAnaliza los datos biométricos.Los modelos de detección de eventos de emergencia requieren una latencia de menos de 50 msPara alertar a los usuarios o al personal médico. Este rápido rendimiento de la IA puede salvar vidas.
Para la IA de borde en tiempo real, la latencia de extremo a extremo importa.El rendimiento computacional sin procesar por sí solo no define el verdadero rendimiento del hardware. La arquitectura de hardware de HiSilicon, con su Da Vinci NPU y aceleradores de hardware dedicados, ofrece este rendimiento crítico de baja latencia. El rendimiento de estos aceleradores de hardware es clave. Los aceleradores de hardware proporcionan un excelente rendimiento.
Nota para los desarrolladores:Debe comparar hardware para la latencia. Esto garantiza el rendimiento y la fiabilidad del hardware en el mundo real. La latencia es importante para el rendimiento de este hardware. Los aceleradores de hardware y el hardware ofrecen este rendimiento. El rendimiento de los aceleradores de hardware es vital. El rendimiento del hardware depende de estos aceleradores de hardware.
Preguntas frecuentes
¿Por qué la latencia es más importante que TOPS para la IA de borde?
TOPS mide el poder de procesamiento en bruto. La latencia mide el tiempo total de una decisión. Para aplicaciones en tiempo real como la conducción autónoma, una decisión rápida es más crítica para la seguridad y el rendimiento que solo un alto rendimiento computacional.
Una latencia baja asegura que el sistema pueda reaccionar instantáneamente a la nueva información.
¿Qué es el Da Vinci NPU?
El NPU Da Vinci es el acelerador de inteligencia artificial especializado de HiSilicon. Utiliza una arquitectura única Cubo 3D para matemáticas de matriz. Este diseño acelera significativamente los cálculos del modelo AI. Reduce directamente la latencia de inferencia y mejora el rendimiento general del sistema para tareas en tiempo real.
¿Cómo los aceleradores de hardware mejoran el rendimiento de la IA?
Los aceleradores de hardware, como un procesador de señal de imagen (ISP), manejan trabajos específicos. Ellos descargan tareas del procesador principal. Este procesamiento paralelo reduce los cuellos de botella. Toda la tubería de IA funciona más rápido, reduciendo la latencia de extremo a extremo y permitiendo una inferencia eficiente en el dispositivo.
¿Qué aplicaciones requieren latencia ultra baja?
Las aplicaciones que necesitan una acción inmediata requieren baja latencia. Estos sistemas dependen de una toma de decisiones rápida y en tiempo real. Ejemplos clave incluyen:
- Sistemas autónomos (vehículos, robótica)🤖
- Infraestructura inteligente (detección de amenazas)🏙️
- Medios avanzados (escalado 8K)📺
- Telemedicina (alertas de emergencia)❤️🩹





