


The シリアル周辺インタフェース(SPI) は有名です高速データ転送を使用します。この同期通信プロトコル効率的なデータを有効にする転送間デバイス、いくつかのデータ転送率 100 MHzを超えるを使用します。だから、なぜあなたのプロジェクトのパフォーマンス常にこれらのトップを打つデータ転送率?あなたの本当のSPIスピードそして全体的にスループット3つの主要分野によって制限されます。
💡最終的なパフォーマンス任意のSPIデータ転送あなたのバランスですデバイス'ハードウェア制限、物理接続品質、およびソフトウェア設定。
重要なポイント
- SPI速度は、デバイスのハードウェア制限、物理接続の品質、ソフトウェアのセットアップ方法の3つの主要なものに依存します。
- マスターデバイスとスレーブデバイスの両方のデータシートの速度制限を常に確認してください。最も遅いデバイスは、SPIバスの最高速度を設定します。
- 良いPCBデザインは重要です。ワイヤーを短くし、トレースの長さに合わせ、強力なグランドプレーンを使用して、高速での信号の問題を防ぎます。
- 直接使用メモリ最高のパフォーマンスのためのソフトウェアのアクセス (DMA)。DMAはあなたのマイクロコントローラメインプロセッサを遅くすることなくデータをすばやく送信します。
SPI速度におけるハードウェアの役割

システムの最大SPI速度を理解するための最初のステップは、ハードウェア自体を調べることです。コード行を作成したり、PCBを設計したりする前に、マスターデバイスとスレーブデバイスのデータシートに厳しい上限が設定されています。あなたの最終的なパフォーマンスは基本的にこれらの能力に結びついています集積回路を使用します。
マスタークロックの制限
マスターデバイス (通常はマイクロコントローラ) は、SPIクロック (SCK) を生成します。このデバイスは、それが動作できる最大周波数を持っていますシリアル周辺インターフェースを使用します。この制限は、データシートの電気特性セクションを使用します。多くの場合、テーブルは最大値を指定しますFSCK(SPIクロック周波数) 異なる動作電圧下。
たとえば、マイクロコントローラのデータシートは、次のようなSPI特性を示します。
| シンボル | パラメーター | 条件 | 分 | Typ | マックス | 単位 |
|---|---|---|---|---|---|---|
| FSCK | SPIクロック周波数 | コントローラ受信機モード2.7 V <VDD< 3.6 V | - | - | 45 | MHz |
| コントローラ送信機モード2.7 V <VDD< 3.6 V | - | - | 45 | MHz |
注:上の表の値はに基づいています
FPCLKx/3、どこでFPCLKxは周辺クロックです。実際の最大値は、マイクロコントローラの特定のアーキテクチャに依存する。
マスター自身のシステムクロックも役割を果たします。SPI周辺機器は、主システムクロックから派生したクロックで動作することが多い。
- マイクロコントローラの内部クロックアーキテクチャは、SPIモジュールの入力クロックを制限し得る。たとえば、モジュールはの最大入力のみを受け入れる可能性があります。48 MHzを使用します。
- この入力クロックは、SPI転送のための最終SCK信号を生成するために分割される。
- これは、SPI周辺機器が理論的に高速で動作できる場合でも、そのパフォーマンスは、フィードする時計によって制限されることを意味します。
スレーブクロック制約
ここで、スレーブデバイスを検討する。すべてのSPIスレーブ、それがaであるかどうかセンサー、メモリチップ、または別のマイクロコントローラも、それが扱うことができる最大クロック周波数を有する。これは、マスター/スレーブ構成における最も重大なボトルネックであることが多い。この制限を超えると、スレーブがデータを誤って解釈し、転送中にデータが破損します。を使用します。
💡SPIバスは、最も遅いデバイスと同じくらい高速です。最終的な通信速度は、2つの最大値 (マスターまたはスレーブ) のうちの低い方に設定する必要があります。
スレーブのデータシートを慎重に確認する必要があります。操作に応じて、異なる最大データ転送レートが表示される場合があります。たとえば、スレーブモードのSTM32マイクロコントローラは、データ受信に40 MHzをサポートする場合がありますが、全二重通信には24 MHzのような低速です。を使用します。これらの違いは、データを同時にサンプリングして送信するために必要な内部ロジックから生じる可能性があります。ほとんどのSPIスレーブデバイスでは、安全な経験則でSPIクロックレートを以下に保つことです。スレーブ自身のシステムクロック周波数の10分の1信頼性の高いデータ転送を保証します。
スレーブ処理遅延
高いクロック周波数は、常に高いスループットに等しいとは限らない。パフォーマンスの真の尺度は、時間の経過とともに転送できるデータ量です。多くのスレーブデバイスは、情報を処理するためにトランザクション間の休止を必要とする。これはとして知られていますスレーブ処理時間またはトランザクション間遅延を使用します。
センサーにコマンドを送信するとします。センサーは、次の転送のためのデータを準備する前に、測定を実行するのに時間が必要です。マスターがスレーブの準備が整うまで長い時間待たなければならない場合、高速SPIクロックは役に立たない。この遅延は、全体的なデータスループットに劇的な影響を与えます。
この遅延が必要な一般的なシナリオは次のとおりです。
| シナリオ | 遅延が必要な理由 |
|---|---|
| スレーブは内部ロジックが遅い | デバイスは、データの前のバイトを処理するために時間を必要とする。 |
| マルチフレームSPIプロトコル | プロトコル自体は、フレーム間に特定の時間ギャップを必要とする。 |
| SPI Flashページの書き込み | メモリチップは、データを書き込む前にアドレスをラッチするために休止しなければならない。 |
| タイミングエラーの回避 | 小さな遅延は、非常に高いSPIクロック速度でエラーを防ぐのに役立ちます。 |
では、スレーブが次の転送の準備ができていることをどのように知っていますか? デバイスは、いくつかの方法を使用してステータスを通知します。
- 忙しいピン:一部のデバイスには、処理中に忙しい信号を送信するためにアサートする専用の出力ピンがあります。
- ステータス登録:スレーブのステータスレジスタをポーリングできます。このレジスタはしばしばのようなビットを含みます
Trdy(送信準備完了) またはRrdyその状態を示すために (receive ready)。 - 割り込み:スレーブは、これらのステータスビットを使用して、マスター上の割り込みをトリガーし、次のSPIトランザクションの準備ができていることをアクティブに通知できます。
シリアル周辺インタフェース物理レイヤ

あなたの限界を理解したら集積回路、それらの間の物理的な接続を確認する必要があります。SPIバスを形成するプリント回路基板 (PCB) のトレースとワイヤは、完全な導体ではありません。高周波では、これらの物理パスは、信号品質を低下させ、全体的なパフォーマンスを制限する可能性のある独自の一連の課題を導入します。
信号経路とレイアウト
長いワイヤとPCBトレースは、小さなアンテナのように機能します。この動作は、信号がマスターからスレーブデバイスに移動するのにかかる時間である伝搬遅延をもたらします。低速では、この遅延はごくわずかです。高いデータ転送速度では、大きな問題となる。
クロック (SCK) とデータ (MOSI/MISO) ライン間のトレース長の不一致により、タイミングエラーが発生します。クロック信号は、データとは異なる時間に受信機に到着する可能性がある。これにより、スレーブデバイスが間違ったデータビットをラッチし、転送全体を破壊する可能性があります。信号周波数が増加すると、クロック周期が短くなり、伝播遅延のわずかな違いに対しても設計がはるかに敏感になります。
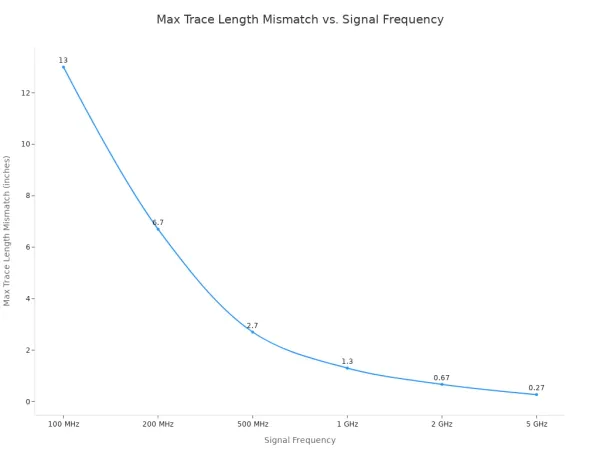
以下の表は、SPIクロック周波数が上昇するにつれて、トレース長の不一致の許容範囲がどれだけ急速に縮小するかを示しています。
| 信号周波数 | クロック周期 (T) | 最大スキュー公差 (20% T) | 伝播遅延 (FR4) | マックストレース長さミスマッチ |
|---|---|---|---|---|
| 100 MHz | 10 ns | 2 ns | 〜150 ps/in | 13 ~ |
| 200 MHz | 5 ns | 1 ns | 〜150 ps/in | 〜6.7インチ |
| 500 MHz | 2 ns | 0.4 ns | 〜150 ps/in | 〜2.7 in |
| 1 GHz | 1 ns | 0.2 ns | 〜150 ps/in | 〜1.3 in |
| 2 GHz | 0.5 ns | 0.1 ns | 〜150 ps/in | 〜0.67 in |
| 5 GHz | 0.2 ns | 0.04 ns | 〜150 ps/in | 〜0.27 in |
プロのヒント:SPIバスが50〜100 MHzの範囲で動作している場合は、トレースを伝送線として扱う必要があります。信号の反射とリンギングを防ぐために、小さなシリーズの終了を追加できます抵抗器(例えば、22〜33Ω) ドライバピンの近く。マスターのSCK、MOSI、およびCSライン上に配置し、各スレーブのMISOライン上に配置します。
バスの容量と完全性
あなたのPCB上のすべての要素、からICピントレース自体に、少量の不要な容量を追加します。これはと呼ばれます寄生容量を使用します。これは、信号トレースとその最も近い参照平面、通常は接地面の間に存在します。それを排除することはできませんが、管理する必要があります。
このキャパシタンスはあなたの信号の立ち上がり時間に直接影響を与えます。立ち上がり時間は、信号が低電圧から高電圧にどれだけ速く移行できるかです。高いバス容量はハードルのように機能し、信号の上昇能力に抵抗しますを使用します。これにより、立ち上がり時間が遅くなり、クロック信号の鋭いエッジが丸められます。クロックエッジが遅くなりすぎると、スレーブデバイスが正しく登録できず、最大クロックレートが制限される可能性があります。興味深いことに、キャパシタンスは信号の落下時間に対する影響がはるかに小さいを使用します。
SPIバスにスレーブデバイスを追加すると、総負荷容量が増加し、信号の完全性がさらに低下する可能性があります。慎重なPCB設計によってこの寄生効果を制御できます。
- より薄い表面層ラミネートを使用する隣接するグランドプレーンへの距離を減らすため。
- 低Dk (誘電体定数) 材料を選択してください総キャパシタンスを下げるあなたのPCBのため。
- リードサイズの小さいコンポーネントを選択する彼らの貢献を最小限に抑えるために。
クロストークとノイズ
クロストークは、1つの信号トレースからの電磁エネルギーが隣接するトレースに「漏れる」ときに発生しますを使用します。PCBでは、これは多くの場合、並んで実行されている2つのSPIトレースの間で発生します。この結合されたエネルギーは、「犠牲者」トレースにノイズを生成します。ノイズが十分に大きい場合、誤った信号遷移を引き起こし、データ転送を破損させる可能性があります。
この現象は主に容量性カップリングによるものです。クロストークやその他の外部ノイズと戦う最善の方法は、適切に設計されたグランドプレーンを使用することです。
ソリッドグラウンドプレーンは、信号電流のための低インピーダンスのリターンパスを提供します。これにより、信号トレースの周りの電磁界が引き締められ、それらが封じ込められ、他の信号と干渉するのを防ぎます。参照平面が近いほど、結合が狭くなり、ノイズが少なくなりますを使用します。
設計を改善し、より高いデータ転送速度を実現するには、次のことを行う必要があります。
- グランドプレーンを最大化する:グランドプレーンには、できるだけ多くの空きスペースをPCBに使用します。
- 専用のグラウンドレイヤーを使う:多層ボードでは、専用のグランドプレーンが優れた分離を提供し、ノイズを低減します。
- ステッチのviasを加える:グランドプレーンを分割する必要がある場合は、ビアを使用して別々の領域を「ステッチ」し、連続した低インピーダンスのパスを作成します。
PCBレイアウト、静電容量、接地を慎重に管理することで、信号の整合性を維持できます。これにより、SPIバスをより高いspi速度で実行し、全体的なスループットを向上させることができます。
SPIパフォーマンスに対するソフトウェアの影響
あなたのハードウェアとPCBレイアウト高速通信の可能性を設定しますが、ソフトウェアは実際にそれを達成できるかどうかを判断します。基本的なプロトコル設定からデータ処理方法まで、コードで行う選択により、最終的なSPIのパフォーマンスとスループットが直接制御されます。
SPIモードとタイミング
The SPIプロトコルは同期です。つまり、マスターデバイスとスレーブデバイスはタイミングに同意する必要があります。正しいSPIモードを選択して、このタイミングを設定します。ここでの不一致は、転送が完全に失敗する原因となります。モードは、スレーブデバイスのデータシート内の2つのパラメータによって定義されます。
- クロック極性 (CPOL):これは、クロック信号のアイドル状態 (ローまたはハイ) を設定する。
- クロックフェーズ (CPHA):これは、データが第1 (先行) または第2 (後続) クロックエッジでサンプリングされるかどうかを決定する。
これら2つの設定を組み合わせて、4つの可能なSPIモードを作成します。マスターがモード0 (CPOL = 0、CPHA = 0) に設定されている場合、立ち上がりクロックエッジでデータをサンプリングする必要があります。データ転送を成功させるには、スレーブデバイスもこのモードに設定する必要があります。これを間違えることは、デバイス間の通信を妨げる一般的なエラーの原因です。
ドライバとOSオーバーヘッド
マイクロコントローラがデータを移動する方法は、パフォーマンスに大きな影響を与えます。通常、SPI転送を処理するには、割り込みまたはダイレクトメモリアクセス (DMA) の2つの選択肢があります。割り込みの使用は基本的な転送の方が簡単ですが、CPUオーバーヘッドが大幅に発生し、最大データ転送速度が制限されます。高性能のために、DMAは優れた方法です。
💡DMAにより、SPI周辺機器はCPUを使用せずにメモリとの間で直接データを転送できます。これにより、CPUが他のタスクを実行できるようになり、システムの効率が劇的に向上し、より高いデータレートが可能になります。
| 特徴 | 割り込み駆動型SPI | DMA駆動SPI |
|---|---|---|
| CPUオーバーヘッド | 高い; CPUはすべてのバイト転送を管理します。 | 低い; 転送を開始した後、CPUは無料です。 |
| スループット | 低い; 割り込みを処理するCPUの機能によって制限されます。 | より高い; 最高のSPIの速度に達することができます。 |
| ケースを使用する | 低レートのために良いセンサーまたは単純なコマンド。 | 高速ストリーミングと大规模なデータブロックに最适です。 |
高解像度ADCやフラッシュメモリなどのコンポーネントから最高のデータ転送速度を達成する必要がある場合は、DMAを使用する必要があります。このアプローチにより、ソフトウェアの遅延が最小限に抑えられ、SPIバスがハードウェアの制限に近づいて動作できるようになります。
最終的なSPI速度は、3つの重要な要素に依存します。これらは、ハードウェアの制限、物理接続、およびソフトウェアの効率です。SPIが知られている高いデータ転送速度を達成するには、3つの領域すべてを考慮する必要があります。高速システムには完全なアプローチが必要です。
💡実用的なテイクアウト:真の最高速度を見つけるには、まずスレーブデバイスのデータシートの制限速度を確認します。次に、PCBレイアウトとソフトウェアでこの速度をテストします。そこから下向きに調整して、特定のプロジェクトの最速の安定率を見つけます。



